정규식과 주요함수들
📌 정규식(Regular Expression)
: 데이터에서 특정한 내용이나 패턴을 찾는 규칙
해당 정규식 기호가 정규식의미를 제거하고 문자 자체로 쓰이기 위해서는 탈출문자(\\)를 이용한다.
. # enter를 제외한 모든 문자
^a # a로 시작하는 단어나 문장
a$ # a로 끝나는 딘어나 문장
[ab] # a나 b가 포함된 단어나 문장
^[ab] # a나 b로 시작하는 단어나 문장 : 대괄호외부 ^
[^ab] # a나 b를 제외한 단어나 문장 : 대괄호내부 ^
^[^ab] # a나 b를 제외한 것으로 시작하는 단어나 문장
# - 은 범위의 이미이다.
[0-9] # 모든 숫자를 포함하는 단어나 문장찾기
[a-b] # 모든 영소문자를 포함하는 단어나 문장찾기
[:alnum:] # 문자와 숫자
[:alpha:] # 문자( 영어, 한글, 한자 )
[:blank:] # 공백( 스페이스, 탭 )
📌 grep() : 데이터 구조 내에서 특정 패턴을 검색한다.
grep( 정규표현식, data, 옵션 )
기본옵션은 해당 데이터가 있는 위치 값을 반환한다.
value=TRUE (value=T)옵션으로 위치가 아닌 해당 데이터값을 직접 출력할 수 있다.
grep_ex <- c("a.txt", "A.txt", "ab.txt", "123.txt", "ba123.txt")
grep("^a", grep_ex) # a로 시작하는 데이터들의 위치
[1] 1 3
grep("^[^0-9]", grep_ex, value=TRUE) # 숫자가 아닌 값들로 시작하는 데이터들의 값
[1] "a.txt" "A.txt" "ab.txt" "ba123.txt"
grep함수는 기본적으로 한번에 1개의 키워드(정규식 규칙)을 통해서만 탐색할 수 있다.
2개이상의 키워드(정규식 규칙)을 동시에 만족하는 것을 찾기 위해서는 연결용함수 paste()에 옵션 collapse를 이용한다.
문자열 결합함수 paste의 기본 옵션은 요소간 구분자는 공백이고( sep=" " ) 요소사이에 결합할 문자열은 없다( collapse="NULL" )
grep_ex <- c("a.txt", "A.txt", "ab.txt", "123.txt", "ba123.txt")
ptn <- c ( "^a", "^A" ) # 2개이상의 키워드 : a로 시작하는 것 & A로 시작하는 것
grep ( ptn, grep_ex, value=TRUE ) # 경고메시지 출력, 첫번째 키워드만 적용해서 탐색하게됨
grep ( paste(ptn, collapse='|'), grep_ex, value=T )
# 벡터의 요소들을 하나의 문자열로 합칠 때 OR논리 구분자(|)로 합친다.
📌 str_replace : 특정 문자열이나 패턴을 다른 것으로 교체한다.
str_replace( string, pattern, replacement )
텍스트분석에 자주 사용되는 외부 패키지 stringr을 설치하여 이용할 수 있다.
install.packages("stringr") # 설치
library("stringr") # 실행txt <- c( "aa.txt", "ba.txt", "ab.txt", "123.txt", "ca123.txt" )
str_replace( txt, 'a', '!' ) # 벡터값들의 특정요소를 치환( 첫번째 요소 )
[1] "!a.txt" "b!.txt" "!b.txt" "123.txt" "c!123.txt"
str_replace_all( txt, 'a', '!' ) # 벡터값들의 특정요소를 치환( 모든 요소 )
[1] "!!.txt" "b!.txt" "!b.txt" "123.txt" "c!123.txt"
str_replace_all( txt, "[0-9]" , "*" ) # 숫자값을 모두 *로 치환
[1] "aa.txt" "ba.txt" "ab.txt" "***.txt" "ca***.txt"
str_replace_all( txt, "\\.", "*" ) # 문자.(meta char)을 모두 *로 치환
[1] "aa*txt" "ba*txt" "ab*txt" "123*txt" "ca123*txt"
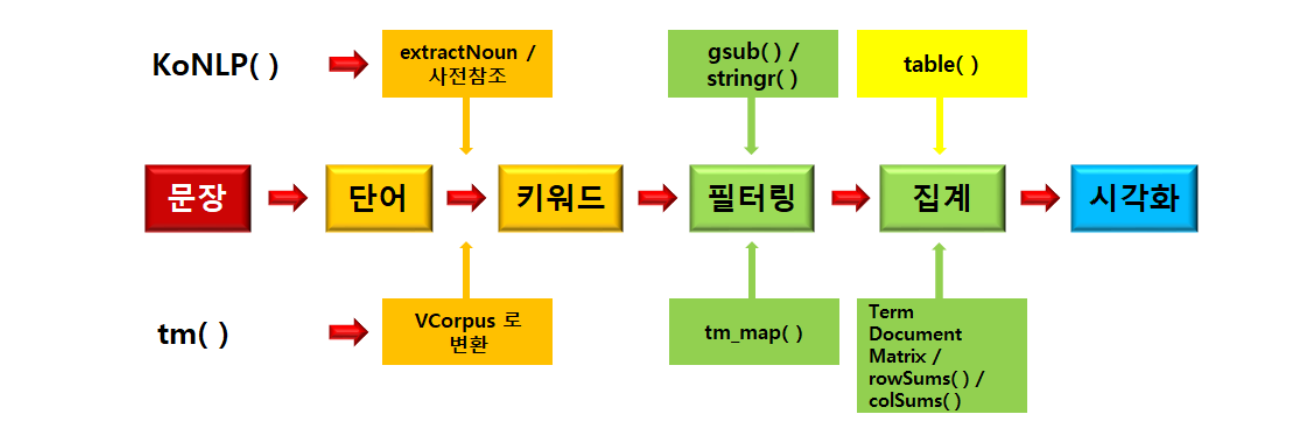
R을 활용한 한글텍스트 분석 및 시각화
텍스트 마이닝(Text Mining)이란 텍스트 데이터를 분석하여 키워드나 의미 있는 정보를 추출하는 과정이다.
다양한 패키지의 함수로 이를 수행할 수 있지만 기본 원리와 동작과정은 거의 동일하다.
문장이 주어지면 공백을 기준으로 나누어 단어를 만든 후 사전을 참조하여 키워드를 찾아낸다.
KoNLP
: R에서 한글 자연어 처리를 위한 패키지로, 다양한 한국어 텍스트 처리 기능을 제공한다.
📌 KoNLP 설치과정
(1) RTools파일을 먼저 설치한다.( R프로그램 종료상태 ) https://cloud.r-project.org/
* RTools : C, C++, Fortran 등으로 작성된 R 패키지를 컴파일하고 빌드하는 데 사용되는 개발도구
(2) KoNLP의 의존성 패키지들을 설치한다.
#Step 1. 의존성 패키지 설치
install.packages(c("cli","hash", "tau", "Sejong", "RSQLite", "devtools", "bit", "rex",
"lazyeval", "htmlwidgets", "crosstalk", "promises", "later", "sessioninfo", "xopen",
"bit64", "blob", "DBI", "memoise", "plogr", "covr", "DT", "rcmdcheck", "rversions"),
type = "binary")
(3) KoNLP의 공식서버가 아닌 깃허브에 업로드된 버전을 설치해야한다. ( 현재 패키지 문제로 install.packages(KoNLP)가 불가능한 상황 )
remote패키지 설치 : GitHub, Bitbucket, GitLab 등과 같은 다양한 소스에서 R 패키지를 설치할 수 있게 해주는 패키지
install.packages("remotes")
이후 KoNLP 깃허브 주소에서 KoNLP 설치
#KoNLP 설치
remotes::install_github('haven-jeon/KoNLP', upgrade = "never", force = TRUE , INSTALL_opts=c("--no-multiarch"))
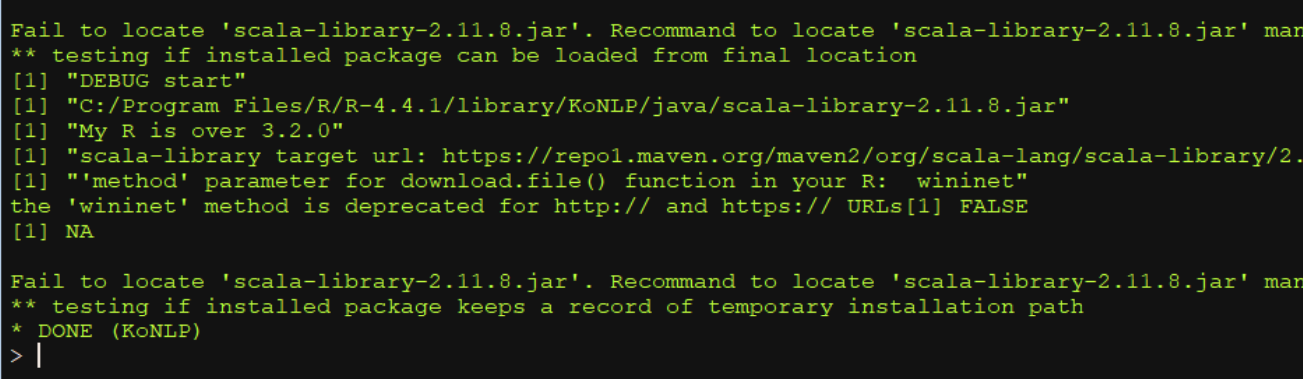
이때 scala-library-2.11.8.jar가 경로( C:/Program Files/R/R-4.4.1/library/KoNLP/java )에 없어서 오류가 발생한다. jar파일을 다운로드 받아서 해당경로에 위치시켜주면 된다.
library(KoNLP)
이후 Checking user defined dictionary! 메시지가 뜨면 정상설치 완료
# 테스트하기
txt <- '나는 사과와 바나나가 좋아요'
extractNoun(txt)
[1] "나" "사과" "바나나"
추가적으로 테스트한 결과 패키지의 정상작동이 이루어졌다.
📌 extractNoun( ) : 한글명사추출함수
: 한글을 입력 받아서 한글 명사를 추출해 주는 역할, Hannanum analyzer(한나눔 분석기)를 이용하여 동작한다.
한줄씩 처리하여 각 문장에 대한 한글명사들을 리스트(list)로 저장한다. ( [[n]] = 줄번호 )
문장별로 처리하기에 문장수가 많으면 시간이 오래걸린다.
data2 <- extractNoun(data1)
data2
[[1]]
[1] "나" "사과" "바나나" "좋아합니다^^"
[[2]]
[1] "나" "바나나" "바나나" "바나나" "바나나" "바나나" "최고"
[[3]]
[1] "나" "복숭아" "사과" "좋아합니다^ㅎ^ㅎ"
[[4]]
[1] "나" "복숭아" "사과" "좋아합니다^ㅎ^ㅎ"
[[5]]
[1] "☎☎☎나는" "사과" "바나나" "좋아합니다☎☎"
[5] "☎"
[[6]]
[1] "나" "파인애플" "복숭아" "좋아합니"
[[7]]
[1] "나는나는파인애플과복숭아를좋아하고바나나도좋고포도와사과도좋아요"
[[8]]
[1] "☜☜☜☜나는" "망고가" "최고" "좋아요☜☜☜" "☜"
동작원리는 공백단위로 자른 후 사전에서 비교(찾음)하여 찾는 것이다.
따라서 사전에 없는 단어는 구별하지 못하고 띄어쓰기가 잘못된 경우 제대로 작동하지 못한다.
v2 <- "봄이지나 면여름이고 여름이지나면가을 입니다"
extractNoun(v2)
[1] "면여름이고" "여름" "이지" "나면" "가을"
📌 사전활용하기
KoNLP설치시 extractNoun에서 사용하게되는 사전이 기본으로 등록된다. ( KoNLP_dic/current/dic_user.txt )
그 양이 절대적으로 부족하기에 분석의 효율성을 높이기위해 CRAN사이트를 통해 배포되고 있는 다양한 최신버전의 외부 사전들을 다운로드 받아서 사용한다. ( SejongDic( ), NIADic( ), woorimalsam )
# 세종사전 사용하기
useSejongDic()
# 이후 옵션1. ALL로 지정
#NIA사전 사용하기 -> 가장 권장되는 최근버전
useNIADic( )
전문분야의 용어, 사람이름과 같은 단어들은 사전에 여전히 등록되지 않은 것들이 많기에 사용자가 분석작업을 하기전 목적에 따라 원하는 단어를 등록(추가)할 수 있다.
mergeUserDic( 데이터프레임( 등록할 단어벡터, 품사벡터 ) )data3 <- "우리는 유관순 의사와 안중근 의사가 독립투사임을 반드시 기억합시다"
extractNoun(data3)
[1] "우리" "유관" "순" "의사" "안중" "근" "의사"
[8] "독립투사" "기억"
# 이름을 하나의 단어로 구분하지 못한다.
# 단어에 이름을 등록
mergeUserDic( data.frame( c('유관순', '안중근'), c('ncn') ) )
extractNoun(data3)
[1] "우리" "유관순" "의사" "안중근" "의사" "독립투사" "기억"
[8] "합"
# 등록한 이름을 단어로 구분한다.
만약 사전에 추가해야 할 내용이 많을 경우는 추가할 단어를 파일로 저장해 둔 후 자동으로 불러서 추가할 수 있다.
mergeUserDic(data.frame(readLines("파일명"), "품사"))
📌 중복되는 값 제거하기
중복 케이스에는 2가지가 존재하며 각자 다른 명령어로 처리하여 중복을 제거한다.
- 여러줄(행)로 문장이 중복 ( unique )
- 한줄(행) 내부에 단어가 중복( lapply + unique )
...
[2] "나는 바나나 바나나 바나나 바나나 바나나가 최고 좋아요!" # 단어중복
[3] "나는 복숭아와 사과를 좋아합니다ㅎㅎ." # 행중복
[4] "나는 복숭아와 사과를 좋아합니다ㅎㅎ." # 행중복
...
unique : 중복되는 행(리스트)를 제거한다. 첫번째 행(줄)만 남겨두고 중복되는 값을 제거한다.
unique(데이터프레임)data5
...
[[2]]
[1] "나" "바나나" "바나나" "바나나" "바나나" "바나나" "최고"
[[3]]
[1] "나" "복숭아" "사과" "좋아합니다^ㅎ^ㅎ"
[[4]]
[1] "나" "복숭아" "사과" "좋아합니다^ㅎ^ㅎ"
[[5]]
[1] "☎☎☎나는" "사과" "바나나" "좋아합니다☎☎"
[5] "☎"
...
data6 <- unique(data5)
data6
...
[[2]]
[1] "나" "바나나" "바나나" "바나나" "바나나" "바나나" "최고"
[[3]] # 리스트의 첫번째 행만 남기고 제거
[1] "나" "복숭아" "사과" "좋아합니다^ㅎ^ㅎ"
[[4]]
[1] "☎☎☎나는" "사과" "바나나" "좋아합니다☎☎"
[5] "☎"
...
lapply : 한줄씩 가져와서 작업을 수행한다.
lapply( 데이터, unique ) # 각 행(리스트)안에서 중복제거작업(unique)를 수행한다.data7 <- lapply(data6 , unique)
data7
...
[[2]] # 리스트 안에서 반복되는 단어 삭제
[1] "나" "바나나" "최고"
[[3]]
[1] "나" "복숭아" "사과" "좋아합니다^ㅎ^ㅎ"
[[4]]
[1] "☎☎☎나는" "사과" "바나나" "좋아합니다☎☎"
[5] "☎"
....
📌 불필요한 단어(불용어:stop word) 삭제하기
(1) 벡터형태에서 제거하기 : gsub() 함수를 이용
(2) 한 글자이하 제거하기 : Filter() 함수를 이용
(3) 문자열에서 특수문자 제거하기 : str_replace_all() 함수를 이용
gsub함수는 특정패턴을 찾아 다른 문자열로 대체한다. 변경후글자를 공백("")으로 지정하여 특정글자를 지우도록 활용할 수 있다.
gsub함수는 반드시 벡터형태에서만 사용이 가능하다. extractNoun 작업후의 리스트형태는 unlist를 통해 벡터로 만들어 이용한다.
gsub("변경전글자" , "변경후글자" , data)data8 <- gsub("최고" , "" , unlist(data7) )
data8
[1] "나"
[2] "사과"
[3] "바나나"
[4] "좋아합니다^^"
[5] "나"
[6] "바나나"
[7] "" # 이 곳에 있던 “최고” 가 삭제됨
[8] "나"
[9] "복숭아"
한글자를 gsub으로 변경하거나 제거하면 한글자를 포함하는 모든 단어에 예외상황이 발생할 수 있다.
Filter함수는 데이터구조(벡터, 리스트)에서 주어진 조건을 만족하는 요소들만 남기고, 나머지 요소들을 제거하는 데 사용된다.
Filter함수는 데이터구조의 요소들중 정의한 함수의 조건을 만족하는 요소들만 추출하여 반환한다.
Filter( function(x){ //필터링 조건 함수 }, 데이터 구조 )Filter( function(x) {nchar(x) <= 10 & nchar(x) > 1} , data)
nachar로 문자열 요소의 글자수를 판단하도록 필터조건함수를 정의하여 한글자, 한글자이하("") 제거작업에 유용하게 이용된다.
data8
[1] "나"
[2] "사과"
[3] "바나나"
[4] "좋아합니다^^"
[5] "나"
[6] "바나나"
[7] ""
[8] "나"
[9] "복숭아"
...
[16] "☎"
[17] "나"
[18] "파인애플"
[19] "복숭아"
[20] "좋아합니"
[21] "나는나는파인애플과복숭아를좋아하고바나나도좋고포도와사과도좋아요"
[22] "☜☜☜☜나는"
[23] "망고"
[24] ""
[25] "좋아요☜☜☜"
[26] "☜"
data9 <- Filter(function(x) {nchar(x) <= 10 & nchar(x) > 1} , data8)
data9 # 의미없는 한글자, 대체작업으로 한글자 미만인 ""를 모두 제거하게 된다.
[1] "사과" "바나나" "좋아합니다^^" "바나나"
[5] "복숭아" "사과" "좋아합니다^ㅎ^ㅎ" "☎☎☎나는"
[9] "사과" "바나나" "좋아합니다☎☎" "파인애플"
[13] "복숭아" "좋아합니" "☜☜☜☜나는" "망고"
[17] "좋아요☜☜☜"
의미없는 특수문자를 제거하기 위해서 stringr패키지의 str_replace_all 을 이용한다.
정규식 패턴을 모든 문자[:alpha:]와 공백[:blank:]을 제거한것[^]으로 하여 제거(교체)한다.
[:alpha:]는 모든문자로 영어, 한글, 한자 등을 모두 포함한다.
# str_replace_all( string, pattern, replacement )
str_replace_all(data,"[^[:alpha:][:blank:]]","")data9
[1] "사과" "바나나" "좋아합니다^^" "바나나"
[5] "복숭아" "사과" "좋아합니다^ㅎ^ㅎ" "☎☎☎나는"
[9] "사과" "바나나" "좋아합니다☎☎" "파인애플"
[13] "복숭아" "좋아합니" "☜☜☜☜나는" "망고"
[17] "좋아요☜☜☜"
data10 <- str_replace_all(data9,"[^[:alpha:][:blank:]]","") # str_replace_all을 이용한 특수문자제거
data10
[1] "사과" "바나나" "좋아합니다" "바나나"
[5] "복숭아" "사과" "좋아합니다ㅎㅎ" "나는"
[9] "사과" "바나나" "좋아합니다" "파인애플"
[13] "복숭아" "좋아합니" "나는" "망고"
[17] "좋아요"
data11 <- gsub("[^[:alpha:][:blank:]]","",data9) # gsub을 이용한 특수문자제거
data11
[1] "사과" "바나나" "좋아합니다" "바나나"
[5] "복숭아" "사과" "좋아합니다ㅎㅎ" "나는"
[9] "사과" "바나나" "좋아합니다" "파인애플"
[13] "복숭아" "좋아합니" "나는" "망고"
[17] "좋아요"
wordcloud
: 단어 구름(워드 클라우드)을 생성하는 데 사용되는 패키지. 단어구름을 통해 스트 데이터에서 단어의 빈도나 중요도를 시각적으로 표현한다.
패키지 설치 및 실행
install.packages(“wordcloud”)
library(“wordcloud”)
기본문법
wordcloud(words,freq,scale=c(4,.5),min.freq=3,max.words=Inf,random.order=TRUE,
random.color=FALSE,rot.per=.1,colors="black",ordered.colors=FALSE,
use.r.layout=FALSE,fixed.asp=TRUE, ...)- words : 출력할 단어들 - table() 함수로 집계를 수행한 후 반환되는 table 객체에서 이름칸(names)
- freq : 언급된 빈도수 - table() 함수로 집계를 수행한 후 반환되는 table 객체
- scale : 글자크기 - c(최대크기, 최소크기)의 벡터값으로 입력, 빈도수가 높은 것과 낮은 것의 글자크기 차이
- min.freq : 최소언급횟수지정. 이 값 이상 언급된 단어만 출력
- max.words : 최대언급횟수지정. 이 값 이상 언급되면 삭제
- random.order : 출력되는 순서를 임의로 지정
- random.color : 글자 색상을 임의로 지정
- rot.per : 일부 단어를 회전시키는 비율을 지정
rotation percent로 0~1사이의 값을 사용 - 0인경우 모든 글자가 가로로, 1인 경우 모든 글자가 세로로, 0.5는 반반, 가장 많이 사용하는 값 - colors : 출력될 단어들의 색상을 지정합니다.
- ordered.colors : 이 값을 true 로 지정할 경우 각 글자별로 색상을 순서대로 지정가능
- use.r.layout : 이 값을 false 로 할 경우 R 에서 c++ 코드를 사용가능
'data' 카테고리의 다른 글
| [ R 프로그래밍 ] 미세먼지관련 소셜키워드 분석 (0) | 2024.08.27 |
|---|---|
| [ R 프로그래밍 ] 제주 여행지 추천 키워드 분석하기 (9) | 2024.08.26 |
| [ R 프로그래밍 ] 경주여행 추천키워드 분석하기 (0) | 2024.08.26 |
| R 프로그램을 활용한 빅데이터 분석특강 - R언어 기본 (4) | 2024.08.24 |
| Tibero DBMS 설치 및 설정 ( Linux, Windows ) (0) | 2024.03.10 |