인터넷에서 “ 제주 여행코스 추천” 키워드로 검색한 결과를 수집해서 어떤 관광지를 추천하는지 주요 키워드를 추출하여 워드 클라우드로 시각화 하는 예제입니다. R코드를 통해 주요키워드를 추출후 word cloud로 시각하고자 합니다.
[ 원본파일 일부내용 ]

(1) 작업 디렉토리 설정하고 필요 패키지 설치 및 실행하기
setwd("c:\\temp")
install.packages("KoNLP")
install.packages("wordcloud")
install.packages("stringr")
library(KoNLP)
library(wordcloud)
library(stringr)
useNIADic()
mergeUserDic(data.frame(readLines("제주도여행지.txt"), "ncn"))
# 사전에 존재하지 않는 제주도 관광지명을 추후 명사화하기 위해 수동으로 추가
(2) 분석할 파일 불러오기
txt <- readLines("jeju.txt", encoding="UTF-8")
head(txt,10) # 잘 불러졌는지 앞부분의 10줄만 보고 확인하기
length(txt) # 분석해야 할 텍스트가 총 몇 줄인지 확인
(2) 명사추출후 중복값, 특수문자 제거
txt2 <- unique(txt) # 중복행(줄) 제거
place1 <- extractNoun(txt2) # 각 행(줄)에서 명사추출하여 리스트화
head(place1,5) # 상위 5행(줄)의 명사리스트 확인
place2 <- lapply(place1, unique) # 각 행(줄)안에서 중복되는 단어 제거하기
(3) 불용어 제거
불용어 제거작업 : 집계작업 -> ( 집계내용으로 불용어 판단후 ) 제거작업을 반복적으로 수행하여 의미있는 데이터만 추출한다.
# 불용어를 찾기 위해서 현재 상태의 단어 중 많이 언급된 순서로 100개 출력 확인
wordcount <- table(unlist(place2))
head(sort(wordcount, decreasing=T),100)
# (1) 한글자는 모두 삭제
place2 <- Filter(function(x) {nchar(x) <= 10 & nchar(x) >1} , unlist(place2))
wordcount <- table(place2)
head(sort(wordcount, decreasing=T),100)
# (2) 불용어 코드로 제거
place3 <- str_replace_all(place2,"[^[:alpha:][:blank:] ]","")
place3 <- gsub("랜드","", place3)
place3 <- gsub("폭포","", place3)
place3 <- gsub("주도","", place3)
place3 <- gsub("이곳","", place3)
place3 <- gsub("구석","", place3)
place3 <- gsub("생각","", place3)
# (3) 단어대체
place3 <- gsub("에코","에코랜드", place3)
place3 <- gsub("퍼시픽","퍼시픽랜드", place3)
place3 <- gsub("애월","애월읍", place3)
place3 <- gsub("정상","수월봉", place3)
# (3) 단어결합
place3 <- gsub(paste(c("성산","일출봉",'성산일출봉'),collapse='|'), "성산일출봉", place3)
place3 <- gsub(paste(c("한라","한라산"),collapse='|'), "한라산", place3)
place3 <- gsub(paste(c("산방","산방산"),collapse='|'), "산방산", place3)
place3 <- gsub(paste(c("녹차","오설록"),collapse='|'), "오설록", place3)
place3 <- gsub(paste(c("천지","지연","천지연폭포"),collapse='|'), "천지연폭포", place3)
place3 <- gsub(paste(c("주상","절리","주상절리"),collapse='|'), "주상절리", place3)
place3 <- gsub(paste(c("만장","만장굴"),collapse='|'), "만장굴", place3)
# 집계작업
wordcount2 <- table(place3)
head(sort(wordcount2, decreasing=T),100)
# 불용어가 많을 파일로 불용어를 삭제한다.
txt <- readLines("제주도여행코스gsub.txt")
txt # 삭제 타켓 단어들을 한줄씩(\n) 불러와서 저장
cnt_txt <- length(txt)
cnt_txt
for( i in 1:cnt_txt) {
place3 <-gsub((txt[i]),"",place3)
}
# 삭제된 키워드의 공백("")제거
place4 <- Filter(function(x) {nchar(x) >= 2 & nchar(x) <= 10} ,place3)
# 재집계
wordcount3 <- table(place4)
head(sort(wordcount3, decreasing=T),30)

(3) 워드 클라우드로 시각화
wordcloud로 시각화
palete <- brewer.pal(7,"Set1")
wordcloud(names(wordcount3),freq=wordcount3,scale=c(5,1),rot.per=0.25,min.freq=4,
random.order=F,random.color=T,colors=palete)
# 시각화된 결과물 저장
savePlot('제주여행키워드_분석.png' , type='png')
wordcloud2로 시각화
install.packages("wordcloud2")
library(wordcloud2)
wordcount4 <- head(sort(wordcount3, decreasing=T),100)
wordcloud2(wordcount4,gridSize=1,size=0.5,shape="star")
임의로 집계내용을 변경할 수 있다.
data54 <- head(sort(wordcount3 , decreasing=T) , 100)
write.table(data54,"data54.txt") # 집계 데이터를 텍스트 파일로 추출하여 집계내역을 확인 & 임의 수정이 가능하다.
data64 <- read.table("data54.txt") # 다시 반영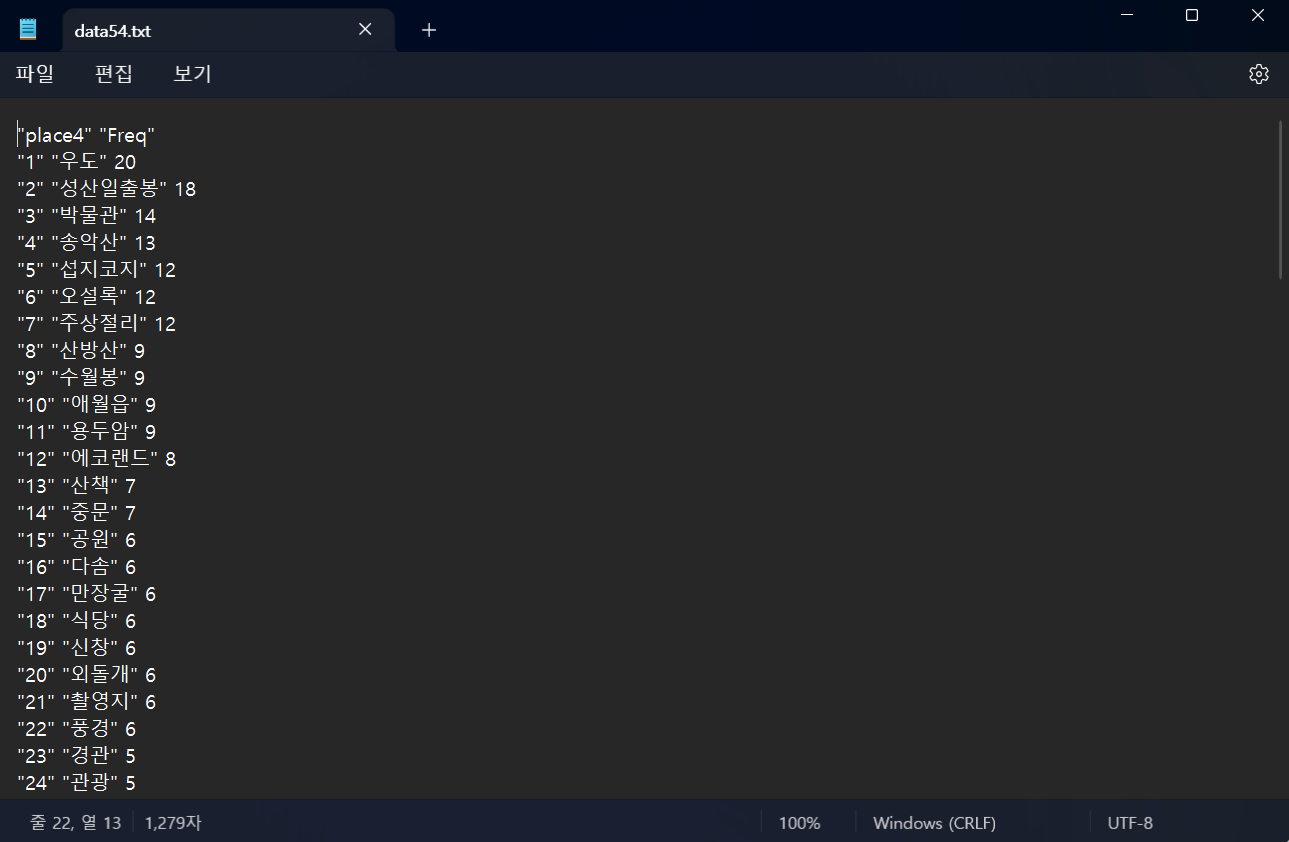
언급된 빈도에 따라 색깔을 다르게 설정하여 표현할 수 있다.
# 10번 이상 언급된 키워드는 빨간색으로 표시하고 나머지는 회색으로 표시하여 강조하고자함
# 조건에 따른 설정내용을 변수에 저장
col <- ifelse(data64$Freq >= 10 , "red" , "gray")
# colors 옵션에 해당 조건변수를 지정
# 텍스트파일(data64)의 각 라벨(place4, Freq)을 이름과 빈도수 옵션에 지정한다.
wordcloud(data64$place4 , freq=data64$Freq , scale=c(4,1) ,rot.per=0.5 , min.freq=1 ,
random.order=F , ordered.color=T , colors=col )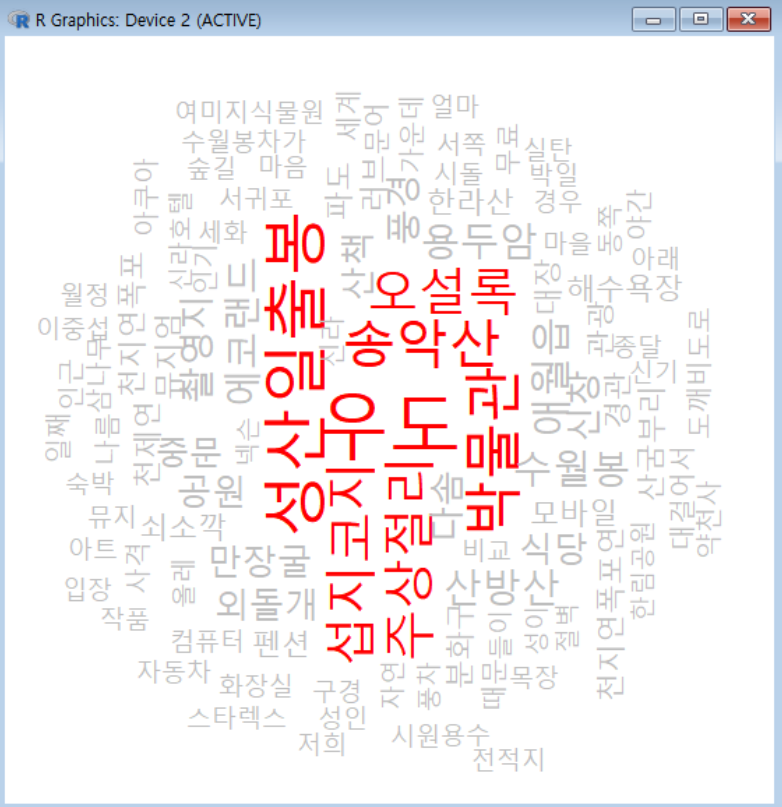
wordcloud2를 이용한 다양한 디자인옵션활용가능
wordcount2 <- head(sort(wordcount, decreasing=T),100)
# wordcloud2(wordcount2,gridSize=1,size=0.5,shape="star")
wordcloud2(wordcount,color = "random-light", backgroundColor = "sky",
fontFamily = '나눔바른고딕')
'data' 카테고리의 다른 글
| [ R 프로그래밍 ] 미세먼지관련 소셜키워드 분석 (0) | 2024.08.27 |
|---|---|
| [ R 프로그래밍 ] 경주여행 추천키워드 분석하기 (0) | 2024.08.26 |
| R 프로그램을 활용한 빅데이터 분석특강 - 데이터처리 (1) | 2024.08.24 |
| R 프로그램을 활용한 빅데이터 분석특강 - R언어 기본 (4) | 2024.08.24 |
| Tibero DBMS 설치 및 설정 ( Linux, Windows ) (0) | 2024.03.10 |