Operating Systems: Three Easy Pieces의 chapter 41~42 / 최종무교수님 운영체제(SW) 강의노트 참고
Chap 41. Locality and the Fast File System
Chap 42. Crash Consistency: FSCK and Journaling
자료들 출처 및 참고 :
https://pages.cs.wisc.edu/~remzi/OSTEP/
Operating Systems: Three Easy Pieces
Blog: Why Textbooks Should Be Free Quick: Free Book Chapters - Hardcover - Softcover (Amazon) - Buy PDF - EU (Lulu) - Buy in India - Buy Stuff - Donate - For Teachers - Homework - Projects - News - Acknowledgements - Other Books Welcome to Operating System
pages.cs.wisc.edu
[ Chap 41 Locality and the Fast File System ]
🍑 Performance requirement
UFS (Unix File System) = VSFS
:: Boot sector + suberblock + bitmap + inode + user data
- Poor Performance : inode와 userdata가 다른 트랙에 위치함, Inode와 Data접근을 교대로(alternately) 수행 ⇒ disk seek가 자주발생, 길어짐


- 장점 : simple & easy-to use
- 단점 : long seek time & consistency
🍑 FFS: Disk Awareness
Fast File System from BSD OS : inode와 user data영역을 가능한 가까이 배치한다.
같은 실린더(same cylinder)에 위치시킴 ⇒ no seek distance
- Cylinder : 여러 platter상에서 같은 트랙에 위치한 블럭들의 집합
- Cylinder group : 서로 다른 surface에서 같은 distance from center를 가진 섹터의 집합

디스크의 파티션(하나의 FS)이 여러개의 실린더 그룹으로 구성됨
그룹의 구성 : superblock ( 모든 그룹에 중복저장 ) + bitmap, inode : 그룹내의 free space, file을 관리( 해당data에 대한 inode를 같은 실린더에 저장 ) + data block

기본적으로 UFS와 동일한 외부인터페이스(external interface)제공한다. ( read, write… ) → 동일한 사용법
그러나 내부 구현(internal implementation)을 다르게 하여 성능향상시킨 파일시스템 모델이다. → 차별화
[ Allocation Policy in FFS : FFS의 할당규칙 3가지 ]
(1) 디렉토리 생성규칙 : 비어있는 inode공간( free inodes )이 많은 실린더 그룹에 생성
load balancing, fairness를 위함 ( even allocation )
(2) 파일 생성규칙 : 소속된 디렉토리와 같은 실린더 그룹에 생성
namespace locality를 고려한 성능향상
이름공간 지역성( namespace locality )이란? 하나의 파일이 참조되면 관련파일(동일한 디렉토리 내의 파일들이)이 함께 참조될 가능성이 높다.
지역성(locality)
: 시간지역성(temporal locality) & 공간지역성(spatial locality) & 이름공간 지역성(namespace locality)


(3) 한 그룹에 저장될 수 있는 최대 블록의 수(chunk) 제한 → 대규모의 파일을 분산하여 저장
디렉토리 하의 파일이 모든 그룹 data영역을 할당받는다면 바람직하지 않음
장점 : locality among files - 같은 디렉토리내 다른 파일들의 지역성함께 보장
단점 : locality in a file - 한 파일내의 지역성 훼손( 다른 그룹에 분산저장 → seek distance )
즉, 파일간의 지역성은 높아지고 파일내 지역성은 낮아진다!


파일의 seek overhead를 계산해보면 규칙3으로 인해 파일내 지역성이 훼손되는 정도를 구해볼 수 있다.
chunk크기만큼을 전송한다고 가정(최대크기를 전송)하고 seek처리가 소요되는 정도( seek time / ( seek time + transfer time ) )를 구해본다.
chunk를 transfer time은 bandwidth(MB/s)(디스크 자체 최대전송량)를 통해 구함 ⇒ ms단위 변환!!!

결과적으로 chunk size가 커질수록 transfer 소요비율(percent bandwidth)이 길어짐 = seek 소요비율은 적어짐( 전체 데이터전송시간이 길어지기에 )
=> Amortization효과( 전체대비 부하의 비율을 미미하게 함 )

[ FFS의 여러 특징 ]
1) 이름공간지역성(namespace locality)를 이용하여 seek distance를 줄임( 연관된 데이터를 같은 그룹에 저장 )
+ 동시에 모든 그룹을 골고루 사용( load balancing ) <-> 이와달리 UFS는 inode가 생성되는 위치가 항상 동일
2) Large disk block 사이즈 : UFS에서 512B(섹터단위) → FFS에서 4KB(블록단위)
→ 단점 : 내부 단편화 발생( 필요보다 더많이 할당가능, Waste space )
→ 장점 : seek time 대비 transfer time이 더 길어짐 ( higher bandwidth ) = amortization
3) sub-blocks( fragment ) allocation : 디스크 블럭을 작은단위로 나누어 할당 → 내부단편화 해결
4) Parameterization placement : 디스크 특성에 따른 배치
순차적 넘버링 대신 교차적 넘버링 → transfer하는동안 만큼의 여유확보
현대 디스크에서는 track buffer를 사용하기에 의미없음

5) Symbolic link를 최초도입 ( 여러 파일시스템간 링크 가능 ) / 이전까지 hard link만 지원
[ Chap. 42 Crash Consistency: FSCK and Journaling ]
🍑 Crash Consistency: FSCK and Journaling
- Consistency : 디스크는 비휘발성(Non-volatility)이기에 문제가 발생하지 않는 상태(valid state)로 지속적 유지필요 ⇒ 방안 : FSCK (File System Check) & Journaling & 이외( 업데이트, COW, 무결성체크, 최적화.. )
- 파일시스템의 지연쓰기( delayed write )( 캐시나 큐를 이용 ) → 전원결함, 시스템문제시 여러 작업중( 다수의 writes ) 일부만 반영될 위험 ⇒ 원자성(atomicity)의 보장이 필요
🍑 The File System Checker( FSCK )
: 모든블럭들을 검사하며 일관성이 깨진 부분들을 체크
- Superblock : FS의 metadata를 저장, sanity check( 식별부호로 값비교 )
- Free blocks 체크 : Bitmap을 inode와 비교 → 주로 inode정보를 우선적으로 follow한다.
- inode 상태체크 : 유효값(음수값, out of bound), inode link count, duplicate pointer check, bad pointer check(범위 벗어남)
- Datablock조사 : file은 불가, directory만 체크가능
⇒ 매우느림(lazy approach), 전체가 아닌 일부만 조사 필요
🍑 Journaling (WAL: write-ahead logging)
: 디스크를 업데이트하기 전에 intend(목표, 의도)를 먼저 적어둠 ⇒ 문제발생시 기록을 보고 redo 혹은 undo처리
active approach → 많은 FS에 이용 (ex. 리눅스의 Ext3 : FFS( 실린더그룹화 ) + 그룹중 하나를 journaling용으로 사용)

저널링의 3가지 형태 : data journal / ordered meta data journal / non-ordered metadata journal
(1) Data Journaling : 기록대상( data, bitmap, inode.. )을 기록하기 전에 TxB, TxE를 추가적으로 기록 ⇒ 원자성 보장
① journaling : 저널그룹에 작성
TxB( transaction begin : Tid, 정보.. )를 기록 + Log기록( 물리적 content, 논리적 intent ) + TxE( transaction end )

② checkpointing : 실제 데이터 그룹에 작성
③ recovery(fault handling)
저널링중( TxB, TxE 기록과정 ) 문제 발생 → undo : 회귀, 과거의 일관상태로
저널링후( 저널링→실제 반영과정 ) 문제 발생 → redo : 다시수행, 미래의 일관상태로
journaling performance overhead : 별도의 기록은 오버헤드를 발생시키지 않는가?
실제로 거의 없음!!( Ext2, Ext3의 비교 ) → 비동기적 성격으로 저널그룹에만 쓰고 실제 반영하지 않아도 응답을 보장해주기까지한다!! 다만, 일련의 기록순서(TxB, 순서대로 기록내용, TxE)의 보장이 요구된다.
이때 개별 write+fsync시 성능악화 → 마지막 TxE 이전에만 fsync 처리를 수행 (=employ commit)
기록순서는 보장할 수 없지만 앞의 요소들이 모두 기록되었음을 보장
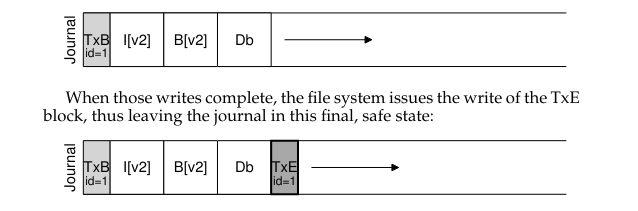
상황별 복구방법 : not commit(end없음) → undo / commit(end있음) → redo
더불어 checksum = end에 대한 해시값, 무결성을 보장
(2) Metadata journaling
Data journaling의 문제포인트는 데이터를 2번적는다는 것이다. large data의 경우 write volume overhead가 커진다!
이에 대한 대안으로 제시된 meta data의 내용만 기록하는 저널링( inode, bitmap / data제외 )

ordered journaling( 순서관계의 필요 ) : 유저데이터보다 메타데이터가 먼저 기록되면 문제발생
최종적인 순서 : data write → meta data journal → journal commit → checkpoint → free
(3) Wirteback = non-orderd metadata journaling : 성능이 더 좋음
Data journaling vs. Metadata Journaling
수평점선은 write barrier를 의미( fsync -> check point)
42.2의 메타데이터저널링은 데이터와 저널링사이 순서관계가 명확하게 정해지지 않은 ext3의 writeback 모드이다.


🍑 Other Approaches( 정리 )
- FSCK : lazy approach
- Journaling : active approach
- Soft update : 파일시스템 업데이트를 강제한다. → not easy to implement( 기술적, 전문적 )
- COW(copy on write) : 기록위치가 아닌 임시위치(복사위치)에 씀, 별도의 버전관리 → 문제 발생시 정상버전으로 교체
- 최적화 : 순서관계를 지키지 않고 기록( 성능향상 ) + checksum으로 일관성(무결성)
🍑 Other File System
(1) 리눅스 파일시스템(Ex)의 변천사
- Ext : UFS( VSFS )
- Ext2 : 성능향상 -> FFS으로 실린더그룹 개념도입, 선할당(8blocks), Read-ahead during sequential reads(다음요청을 미리 읽어두기)
- Ext3 : Ext2 + 저널링( 1개의 저널링그룹, 이때 checkpoint이후 저널링기록 삭제 )
- data journal, ordered, write back의 3가지 유형 → 일관성 향상
- Ext4 : Ext3 + extent개념으로 대용량파일(huge file)지원
- Extent : 가변크기 포인팅 가능 ↔ Inode는 고정크기 4KB씩 포인팅 가능
extent tree에서 split/merge로 관리 - Extent-based mapping : inode에서 indirect block(pointer)대신, extent단위로 데이터블럭을 참조한다.( direct처리가능 )
- Extent : 가변크기 포인팅 가능 ↔ Inode는 고정크기 4KB씩 포인팅 가능

(2) FAT filesystem( Originated by Microsoft )
- metadata block역할을 한번에 수행하는 FAT(File Allocation Table) = bitmap + inode 이용
- metadata의 양을 줄임으로써 small storage에서 메타데이터를 위한 공간을 절약할 수 있다!
- bitmap의 역할 : Used for used/free
- inode의 역할 : data location (다음블럭으로 연결) / 파일별로 존재 ↔ fat은 fs별로 존재(모든파일)
- 파일시스템의 구성 : boot block(1) + FAT blocks(2) +root directory(1)
- root directory는 inode번호가 아닌 cluster를 저장
- FAT : bitmap table( 메타데이터에 RES, 할당 데이터에 주소값 )
- 다음 cluster index값을 저장, 파일의 마지막 cluster는 EOF저장
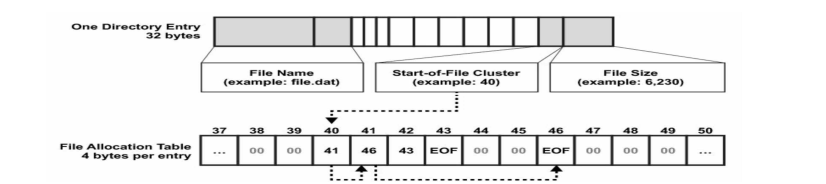
- 처리 방식 : Directory entry( 메타데이터 저장 : filename, size, Start of file cluster : FAT index(cluster)를 가르킴 ) → FAT( 각 entry(cluster)는 다음 entry index(cluster)를 저장 → 마지막 엔트리(cluster)는 EOF를 저장 )
(3) Flash-aware FS
- flash memeory : 디스크처럼 비휘발성(non-volatile)의 기기 -> 영속성 스토리지로 활용가능!
- erase operation필요 : 디스크는 read/wirte( update는 덮어쓰기 ) ↔ 플래시 메모리는 read/write/erase( update는 erase→write)
- 수명(endurance)의 한계 = erase의 횟수제한
- read/write unit(작은단위)와 erase unit(큰단위)이 상이함 → 소프트웨어로 제어
- 전자기적으로 작동( ↔ 디스크는 기계적운동 ) ⇒ 빠름(performance), 충격강함(shock resistence), 비쌈
- Out-of-place update : 다른공간에서 갱신해당위치가 아닌 new 블록 allocate & write작업 → 기존 공간으로 mapping(복사) ↔ 제자리 갱신(in-place update) : already allocated blocks에서 wirte
- 쓰레기값이 되는 기존의 블럭( old invalidated blocks )은 언젠가 수집하여 반환( garbage collcetion )

- F2FS( Flash Friendly FS ) by Samsung
- FFS기반(inode이용) + out of place update
- Translation (mapping) : 새로운 inode를 생성하여 old data에 매핑 ⇒ GC가 처리
- Wear-leveling : 모든 영역에 골고루 erase되도록 함
- FTL (Flash Translation Layer) : 플래시 메모리의 기능을 디스크처럼 추상화 → 디스크처럼 write, read만 작동하는 것처럼 보임
'computer science' 카테고리의 다른 글
| [MultimediaSystem] Image Compression & Image Processing (1) | 2024.06.23 |
|---|---|
| [MultimediaSystem] Color depth / Color model / Color space (0) | 2024.06.23 |
| [MultimediaSystem] Vector graphic & Bitmap image (0) | 2024.06.22 |
| [ OSTEP ] File System Basic (0) | 2024.06.21 |
| 운영체제 Shell기능 직접구현해보기(MyShell.c) (0) | 2024.03.10 |