
서론 : 프로젝트 개요
개발동아리에서 한학기동안 간단한 딥러닝 프로젝트에 참여하였다.
프로젝트 주제는 FakeFace Detection 으로 (GAN모델을 통해 인위적으로) 생성된 사람얼굴이미지(Fake)와 실제 사람얼굴이미지(Real)를 분류하는 분류기를 구축하는 것이다.

프로젝트의 전반적인 구조는 다음과 같다.
1) GAN모델을 통해 인위적으로 사람얼굴이미지를 생성한다. (이미지 생성모델)
GAN이란? 가짜이미지를 만들어내도록 학습되는 생성자(Generator)와, 가짜와 진짜 이미지를 구별하는 감별자(Discriminator)를 경쟁시켜 학습하면서 최종적으로 생성자가 진짜와 같은 이미지를 만들어내게 되는 딥러닝 모델이다.
2) Resnet모델을 통해 인위적으로 생성된 이미지(fake)와 실제 이미지(real)를 분류한다. (이미지 분류모델 = classfier)
역할분담은 GAN모델 구현 2명( 생성자, 감별자 ) + Resnet모델 구현 1명 + 데이터 전처리 1명으로 구성하였고, 나는 데이터 전처리를 담당하였다.
시간상 모델을 연동하여 도커환경에서 실행하는 단계까지는 나아가지 못하고 개별적으로 코랩환경에서 모델을 구축하고 학습하는 단계까지 진행하였다.
데이터전처리의 역할에서 2개의 모델을 위한 2개의 데이터로더를 작성하였다. ( 이미지 분류기(Resnet) 학습용 데이터로더 & GAN 학습용 데이터로더 )
2개의 로더를 처음에는 Pytorch로 작성하였고 이후에 PytorchLightning으로 작성하는 연습을 하였다.
데이터셋의 선정 : CelebA
Celeb datasets은 20만개 이상의 유명인 이미지에 40개의 속성, 10,177개의 신원가 포함된 대규모의 이미지 데이터셋이다.
대규모 데이터셋으로 구글 드라이브에 올리면 런타임 시간초과 에러가 발생하기에 압축파일(zip)을 올려 사용시 압축해제시키는 방법을 사용하였다.
에서 해당 데이터셋을 구글 드라이브에 다운로드( 링크 : https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html ) & 코랩에 구글 드라이브를 마운트 한뒤 ( drive.mount('/content/drive') ) 에 읽어오기 작업을 수행하였다.
CelebA Dataset
Details CelebFaces Attributes Dataset (CelebA) is a large-scale face attributes dataset with more than 200K celebrity images, each with 40 attribute annotations. The images in this dataset cover large pose variations and background clutter. CelebA has larg
mmlab.ie.cuhk.edu.hk

Pytorch를 이용한 데이터로더 작성연습
( 참고문헌 : [Must Have] 텐초의 파이토치 딥러닝 특강 )
1) 다양한 파이토치 라이브러리(복습)
[ 데이터 전처리 관련 라이브러리 ]
- torchvision.transforms : PyTorch의 이미지 변환(transformations) 모듈, 이미지 데이터셋을 전처리하고 데이터 증강하기위한 다양한 변환 함수들을 제공
- Compose(합성): 여러 변환을 연결하여 하나의 변환으로 만드는 기능, 변환 목록을 받아서 입력 데이터에 순차적으로 적용
- ToTensor(텐서로 변환) : PIL 이미지나 넘파이 배열을 PyTorch 텐서로 변환 PyTorch의 형식 : 데이터를 [0.0, 1.0] 범위의 부동 소수점으로 변환 & C x H x W (채널 x 높이 x 너비)로 차원 재배열
- RandomHorizontalFlip(랜덤 수평 뒤집기) : 이미지를 주어진 확률에 따라 수평으로 뒤집는 변환 ( 기본값 0.5 ) → 무작위로 수평으로 뒤집어 다양한 관점을 제공 ( + RandomVerticalFlip : 랜덤 수직 뒤집기 )
- RandomCrop(랜덤 자르기) : 주어진 크기에 따라 이미지의 일부의 위치를 무작위로 자르는 변환 → 데이터셋의 다양성을 높여주는 역할
- Normalize(정규화) : 평균과 표준편차를 사용하여 이미지의 각 채널을 정규화
[ 데이터셋 관련 라이브러리 ]
- DataLoader 클래스( torch.utils.data.DataLoader ) : 데이터셋을 배치 단위로 로드하고 셔플(shuffle) 및 병렬 처리(parallel processing)를 지원
DataLoader 객체는 batchsize만큼으로 미니배치를 묶음 → 반복문을 통해 각 배치(batch)단위 접근가능
DataLoader( 로드한 datasets, batch_size=한번에 로드할 데이터수, shuffle(섞기여부)=True/False )
- ImageFolder 클래스 ( torchvision.datasets.ImageFolder ) : 경로를 넣어주면 자동으로 이미지를 읽어와주는 편리한 토치비전의 객체
디렉토리 구조에 기반하여 이미지 데이터셋(datasets객체)을 로드 → 데이터셋 폴더에 구분하여 저장하여 사용가능
dataset = ImageFolder(root=최상위경로(클래스이름으로 나누어놓은 폴더들의 최상위폴더), transform=데이터 변환 객체(transform))
[ 이미지 시각화관련 라이브러리 ]
- PIL.Image : 이미지 파일의 로드
- matplotlib.pyplot : 이미지파일의 시각화
2) GAN 학습용 데이터로더
코드 코랩주소 : https://colab.research.google.com/drive/15XMl78gp4Tdh91hvGPRV35bw6QDa10kU
(1) 이미지 전처리 : 64X64크기로 변환 → 가운데를 오려냄 → 다시 64X64크기로 업스케일링
#이미지 전처리
transforms = tf.Compose([
tf.Resize(64),
tf.CenterCrop(64),
tf.ToTensor(),
tf.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
(2) 데이터로더 작성
dataset = ImageFolder(
root="./GAN",
transform=transforms
)
loader = DataLoader(dataset, batch_size=128, shuffle=True)
3) Resnet 학습용 데이터로더
코드 코랩주소 : https://colab.research.google.com/drive/1ii7GGJvfkFQEL3v5E6IHK6m0VwTFLpKp
실제로는 GAN에서 생성한 이미지랑 CelebA 데이터를 호출하는 데이터셋을 만들어야 되는데 아직 GAN이 완성되지 않아 예제대로 데이터셋 CIFAR10으로 작성
(1) 이미지 전처리 : 32X32크기로 무작위 위치의 이미지를 잘라내고 패딩 → 0.5의 확률로 수평 뒤집기
transforms = Compose([
RandomCrop((32, 32), padding =4),
RandomHorizontalFlip(p=0.5),
ToTensor(),
Normalize(mean=(0.4914, 0.4822, 0.4465), std=(0.247, 0.243, 0.261))
])
(2) 학습용, 테스트용 데이터셋 작성
train_loader = DataLoader(training_data, batch_size=32, shuffle=True )
test_loader = DataLoader(test_data, batch_size=32, shuffle=False )
PytorchLightning을 이용한 데이터로더 작성실습
1) 다양한 파이토치 라이트닝으로 데이터 전처리
파이토치 라이트닝이란?
파이토치 라이트닝(PyTorch Lightning)은 PyTorch를 기반으로 한 딥러닝 프레임워크로, 연구와 개발을 보다 간단하고 효율적으로 할 수 있도록 도와줍니다.
데이터셋의 모델 정의, 데이터 로딩, 학습 절차 등을 독립적으로 모듈화하여 코드의 재사용성과 유지보수성을 높였다.
또한 콜백시스템, 자동화시스템( 체크포인팅, 로깅, 분산 학습, 프로파일링 등의 기능 )으로 효율적인 모델작동을 가능하게 한다.
[ LightningDataModule ]
: 파이토치 라이트닝에서 데이터를 처리하고 모델에 공급하는데 사용되는 모듈
- init : 인스턴스를 생성할 때 호출, 초기화
- prepare_data() : 데이터를 다운로드하고 준비 / 경로설정, 사전처리 및 변환, 각 프로세스에서 한 번만 호출
- setup(stage) : 데이터로더 설정, 각 프로세스에서 한 번만 호출
- stage = fit : 학습 및 검증 데이터를 설정
- stage = test : 테스트 데이터를 설정
- train_dataloader() : 학습데이터에 대한 데이터로더 반환
- val_dataloader() : 검증데이터에 대한 데이터로더 반환
- test_dataloader() : 테스트 데이터에 대한 데이터로더를 반환
[ PyTorch Lightning의 데이터 모듈 라이프사이클 ]
- init : 데이터 모듈 객체가 생성될 때 호출, 주로 데이터 모듈의 속성을 초기화하고, 필요한 설정을 지정
- prepare_data : 단 한 번 호출, 데이터셋의 다운로드, 압축 해제, 데이터베이스 쿼리 등 I/O 관련 작업
- setup : 각 학습 단계 (train, val, test)에서 호출, 데이터셋을 분할하고 데이터셋을 로드
이는 PyTorch Lightning의 트레이너가 호출순서 자동관리 : 객체 생성시 init자동호출 → prepare_data → setup
사용법1) 명시적 호출
data_module = CelebaGANDataModule(celeba_dir, gan_dir, batch_size=batch_size)
# 데이터 모듈 객체 생성 후, prepare_data 및 setup 호출 순서 확인
data_module.prepare_data() # 명시적 호출
data_module.setup() # 명시적 호출
# 학습 단계에서 데이터 로더 호출
train_loader = data_module.train_dataloader()
val_loader = data_module.val_dataloader()
test_loader = data_module.test_dataloader()
사용법2) 자동호출
from pytorch_lightning import Trainer
# 모델 정의 생략 (예: ResNet 기반 모델)
model = ...
data_module = CelebaGANDataModule(celeba_dir, gan_dir, batch_size=batch_size)
# 트레이너 설정
trainer = Trainer()
# 모델 학습 시작
trainer.fit(model, datamodule=data_module) # 이 과정에서 prepare_data -> setup -> train_dataloader 호출됨
trainer.validate(model, datamodule=data_module) # setup -> val_dataloader 호출됨
trainer.test(model, datamodule=data_module) # setup -> test_dataloader 호출됨
2) GAN 학습용 데이터로더작성( CelebADataModule )
코드 코랩주소 : https://colab.research.google.com/drive/18NkPlyqdmAZ1Z1wGWGgmg-TiUC4-2DwF#scrollTo=CFuVhTT1xVNz
CelebADataModule.ipynb
Colab notebook
colab.research.google.com
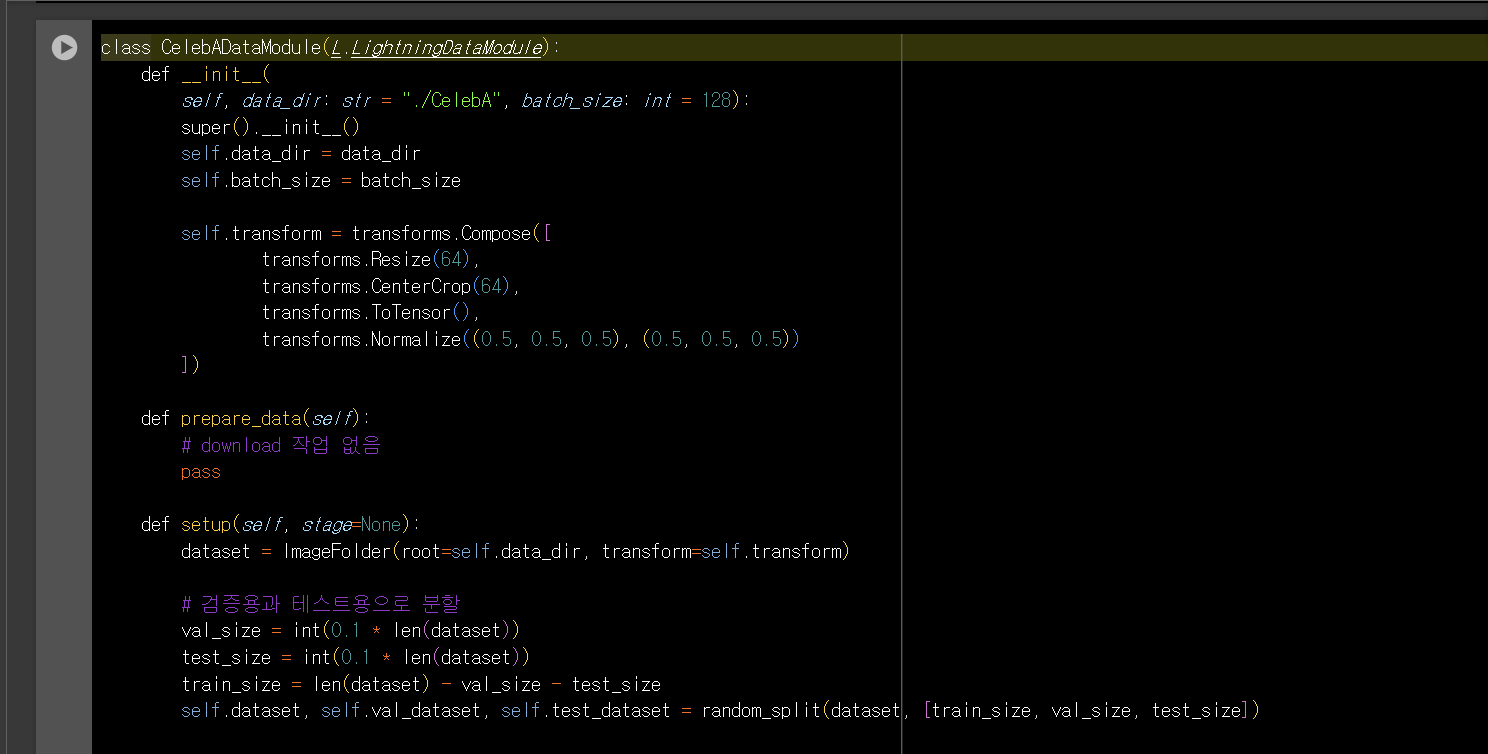
- setup로 데이터셋을 설정한다.
- train_dataloader로 학습 데이터로더를 반환한다.
- val_dataloader와 test_dataloader는 GAN의 특성상 생략하거나 필요에 따라 구현한다.
CelebA 데이터셋은 일반적으로 학습용 데이터만을 포함하고 있으며 별도의 검증용 또는 테스트용 데이터셋은 제공하지 않는다. 이러한 경우에는 학습 데이터셋을 학습, 검증 및 테스트 세트로 분할하여 사용하는 것이 일반적이다.
하지만 생성 모델인 GAN(Generative Adversarial Network)의 경우 별도의 검증 및 테스트는 필요하지 않다. 따라서 pass로 넘길 수 있다.
def train_dataloader(self):
# 학습 데이터로더
return DataLoader(self.dataset, batch_size=self.batch_size, shuffle=True)
def val_dataloader(self):
pass
def test_dataloader(self):
pass

이후 명시적으로 setup한뒤에 train loader를 불러와서 8X16으로 결과를 확인해보았다.
3) Resnet 학습용 데이터로더작성( CelebAGANDataModule )
코드코랩 주소 : https://colab.research.google.com/drive/136V6R-simE8S0Egzk6ySHzRmsuDgKtNh
Google Colab Notebook
Run, share, and edit Python notebooks
colab.research.google.com
분류기를 학습하기 위해서 GAN모델에서 생성된 이미지(gan_images)와 CelebA의 이미지(celeba_images)를 함께 불러와야한다.
먼저 두 개의 별도 디렉토리에서 이미지를 로드하고 레이블링하는 커스텀 데이터셋 클래스인 CelebAGAN datasets을 구축하였다.

데이터셋의 정의할때 상속받는 클래스인 torch.utils.data.Dataset을 이용한다.
- __init__ 메서드 : 데이터셋을 초기화하고, 이미지와 레이블을 준비 -> 각 디렉토리에서 이미지를 가져와 합치고 순서대로 라벨링 작업( 생성된 이미지(gan_images) = 1, CelebA의 이미지(celeba_images) = 0 )
이후 combined 리스트로 이미지와 레이블을 쌍으로 묶은 후, 이를 섞어 데이터셋을 구성하였다. - __len__ 메서드 : 데이터셋의 크기를 반환 -> 배치 크기로 활용
- __getitem__ 메서드 : 인덱스를 받아 해당 인덱스의 이미지와 레이블을 반환

setup메서드에서 데이터셋을 로드하여 학습용, 검증용, 테스트용으로 분할하였다.

검증이랑 테스트를 위한 데이터셋은 각각 10%씩 할당하였고 전체적인 배치사이즈는 128개로 생성하였다.

'machine learning & deep learning' 카테고리의 다른 글
| RNN(순환신경망), LSTM(장단기메모리) 실습 : 주가분석, 영화리뷰분석 (0) | 2024.03.10 |
|---|---|
| Computer vision에서의 딥러닝 : OpenCV & U-net (0) | 2024.03.10 |
| 합성곱신경망 : CNN(conventional Neural Network) (0) | 2024.03.10 |
| 머신러닝 기초 & MLP 인공신경망 (0) | 2024.03.10 |