
23.10.01
MNIST 데이터셋 가져오기
MNIST : PyTorch의 torchvision 라이브러리에서 제공되는 손으로 쓴 숫 이미지 데이터 ( 28x28x1 (784픽셀)의 흑백 이미지 )

MNIST 데이터셋을 128배치크기만큼 불러온다.
train_dataset = MNIST( root='./', train=True, transform=transforms.ToTensor(), download=True )
test_dataset = MNIST( root='./', train=False, transform=transforms.ToTensor(), download=True )
train_loader = DataLoader(dataset=train_dataset, batch_size=128, shuffle=True)
test_loader = DataLoader(dataset=train_dataset, batch_size=128, shuffle=True)
val_loader = test_loadertrain_dataset에 6만개, test_dataset에 1만개의 이미지 데이터가 저장된다.
=> 미니배치를 만들어서 128개씩 읽어오도록 한다.
각 모델의 성능비교를 위한 공통모듈 구현
:: train 함수, 복잡도계산 함수로 모델 성능비교
- 재사용가능한 train함수 구현
:: 구현한 model , 데이터(배치loader)을 입력하면 10번단위 epoch으로 adam옵티마이저가 가중치 업데이트 하면서 학습한다. (크로스 엔트로피의 loss함수를 이용)
매번 학습이 끝난후에는 같은 학습데이터에 대해서 얼마나 잘 맞추는지의 정확도를 구하고, 학습에 걸린시간도 구해주는 역할을 수행한다.
from torch import optim
import time
def train(model, train_loader): #train loader만 바꿔서 재사용이 가능
epochs = 10
optimizer = optim.Adam(model.parameters(), lr=0.0001) #optimizer 세팅
criterion = nn.CrossEntropyLoss() #Loss함수 세팅 -> 크로스 엔트로피로 설정
start_time = time.time() #시작시간
for epoch in range(epochs): #0~9
model.train() #model을 train모드로 변경
print(f'epochs:{str(epoch+1)}/{str(epochs)}') #현재 epoch
for samples in train_loader: #하나의 배치에 대한 학습진행
x_t, y_t = samples
#각각의 x_t와 y_t를 deivce(GPU)라고 하는 곳으로 보내야함
x_t = x_t.to(device)
y_t = y_t.to(device)
#데이터를 모델에 넣는다 -> x_t데이터를 가지고 forward연산이 실행된다.
pred = model(x_t)
#loss를 구한다. 정답과 예측값의 차이(loss)를 구한다.
loss = criterion(pred, y_t)
#구한 loss를 바탕으로 역전파 학습을 진행한다. adam optimizer를 사용합니다
optimizer.zero_grad() #optimizer 초기화
loss.backward() #역전파 진행
optimizer.step() #역전파된 것을 기반으로 가중치 업데이트
#배치 내의 모든 샘플에 대한 학습이 완료된 상태 -> 성능 테스트 수행
model.eval() #모델을 평가모드로 변경
correct = 0
for samples in train_loader :
xx, yy = samples
xx = xx.to(device)
yy = yy.to(device)
#모델에 집어넣기
pred = model(xx) #10개의 값이 리스트로 나온다 [ 0, 0, 0, 0, 0.1, 0.7, 0.1, 0.1, 0, 0 ]
_, predicted = torch.max(pred, 1) #최대값 인덱스만 저장 (값은 무시)
correct += predicted.eq(yy.data).sum()
print(f'train accuary : {100. * correct/len(train_loader.dataset)}') #학습데이터중 맞춘것에 대한 백분율 값
end_time = time.time()
지난시간 = end_time - start_time
분 = int(지난시간//60)
초 = int(지난시간%60)
print(f'현재까지 학습하는데 걸린 시간 : {분}분 {초}초')
- 재사용 가능한 복잡도계산 함수 구현
: 모델에서 parameter를 하나씩 꺼내와서 해당 사이즈를 모두 더해본다.
def 복잡도계산(model) :
pp = 0 #전체파라미터 사이즈
for p in list(model.parameters()): #파라미터 1개 추출
nn=1 #파라미터 1개의 사이즈
for s in list(p.size()): #각 parameter 사이즈 리스트
nn = nn*s
pp += nn
return pp
- 재사용 가능한 테스트 함수 구현
def test(model, test_loader):
with torch.no_grad():
model.eval() #모델을 평가모드로 변경
correct = 0
for samples in test_loader:
xx, yy = samples
xx = xx.to(device)
yy = yy.to(device)
#예측수행
pred = model(xx)
#예측된 값이랑 얼마나 차이가 나는지 확인
_, predicted = torch.max(pred,1)
correct += predicted.eq(yy.data).sum()
print(f'test accracy : {(100. * correct / len(test_loader.dataset)).item()}')
MLP(Multi Layer Perceptron)를 이용한 MNIST 분류모델 구현
- nn.Seqential : 신경망 모델 구축 클래스 / 내부적으로 nn.Module을 자동으로 상속받게 된다.
- nn.Flatten() : 다차원 텐서를 1차원으로 평탄화 => FCL(fully conected layer)를 구축하기 위함
mnist_fc_model = nn.Sequential(
nn.Flatten(), #이미지를 일렬로 나열
nn.Linear(in_features=28*28, out_features=256), #MLP
nn.Sigmoid(),
nn.Linear(in_features=256, out_features=10), #분류하고자하는 클래스 수는 10개
nn.Softmax() #각 클래스일 확률이 나옴
)
트레이닝 결과(def train) : 초기의 낮은 정확도에 비해 학습을 거치면 높은 정확도를 가지게되는 것을 볼 수 있다. (GPU이용)

복잡도 검사결과(def 복잡도검사) : 복잡하고 무거움

* MLP(Multi Layer Perceptron)의 한계점과 인공지능 암흑기
- 깊어진 층에서 발생하는 많은 parameter를 연산할 능력부족
- 네트워크를 거치면서 데이터의 위치정보가 소실된다는 문제점

CNN(conventional Neural Network)을 이용한 MNIST 분류모델 구현
* CNN(Convolutional Neural Network) (합성곱 신경망) 의 기본원리
3차원 데이터 이미지를 받아서 3차원으로 전달한다. ( 합성곱연산을 통한 2차원행렬을 n개 전달 )


합성곱 : 행렬의 곱연산과는 다른 개별매칭 곱의 합 / 이후 편향까지 더해준다.

mnist_cnn_model = nn.Sequential(
#MNIST 사용할 예정, 1X28X28 (채널1)
nn.Conv2d(in_channels=1, out_channels=4, kernel_size=3, padding=0),
nn.ReLU(),
nn.Conv2d(in_channels=4, out_channels=8, kernel_size=3, padding=0),
nn.ReLU(),
#CNN모델의 NLP부분(마지막 출력)
nn.Flatten(),
nn.Linear(in_features=24*24*8, out_features=48), #마지막 conv 레이어의 출력채널을 고려
nn.ReLU(),
nn.Linear(in_features=48, out_features=10),
nn.Softmax()
)
* Convolution layer(nn.Conv2d)의 구성요소
- in_channels : 입력형상
- out_channels : 출력형상 => 높을수록 더 많은 특성을 추출할 수 있지만 비용증가, 과적합의 문제를 고려해서 결정
(* 하나의 레이어에서 하나의 필터로만 합성곱연산을 수행하지 않는다 -> 각 레이어의 입력채널 = 전 레이어의 출력채널 )
- kernel_size : 합성곱 연산을 위한 필터의 크기(정방형 n*n)
커널의 크기가 커지면 큰 물체를 detect하기 쉽고, 커널의 크기가 작아지면 작은 물체를 detect하기 쉬워진다.

- stride : 필터를 적용하는 간격 -> 간격이 커질수록 출력데이터(피처맵)의 크기가 작아진다.
- padding : 합성곱 연산시 피처맵이 작아지지 않도록 하기위해 빈 공간을 채우는 것
=> zero padding(0) , constant padding(특정상수), reflection padding, replication padding


트레이닝 결과(def train) : 초기부터 높은 정확도를 가졌고 학습을 통해 정확도가 더 높아지는 모습이다. (GPU이용)
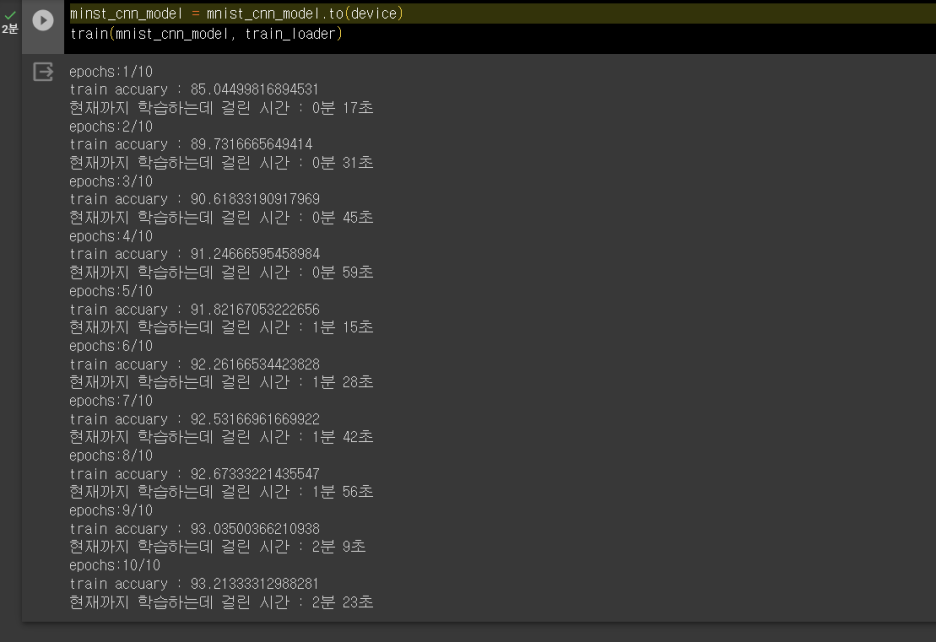
복잡도 검사결과(def 복잡도검사 ) : 복잡하고 무거움

LeNet을 이용한 MNIST 분류모델 구현
LeNet-5 : 최초의 CNN모델(1998)
* pooling layer
: 합성곱으로 도출된 feature벡터의 크기를 절반으로 줄여주는 작업 => 최대풀링(max pooling), 평균풀링(average pooling)
(1) 학습매개변수가 없음
(2) 채널수가 그대로 유지됨
(3) 변화(입력데이터의 변동성)에 영향이 적다

- nn.Tanh() : 하이퍼볼릭탄젠트를 활성함수로 사용 -> sigmoid보다 분포가 넓음
- nn.AvgPool2d() : 2D 평균 풀링(average pooling) 연산을 수행, kernel_size만큼의 정방형 윈도우 단위로 pooling 진행=> 르넷은 서브샘플링으로 해당효과를 구현했다.
lenet = nn.Sequential(
nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, stride=1),
nn.Tanh(),
nn.AvgPool2d(kernel_size=2), #subsampling을 대체 - 2X2의 4개 값을 하나의 평균값으로 반환
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1),
nn.Tanh(),
nn.AvgPool2d(kernel_size=2),
nn.Conv2d(in_channels=16, out_channels=120, kernel_size=4, stride=1), #1X1이 120개 도출된다
nn.Tanh(),
#Linear 레이어(MLP)
nn.Flatten(),
nn.Linear(in_features=120, out_features=84),
nn.Tanh(),
nn.Linear(in_features=84, out_features=10),
nn.Softmax()
)
트레이닝 결과(def train) : 초기 정확도, 후기 정확도 모두 더욱 높아졌다. (GPU이용)
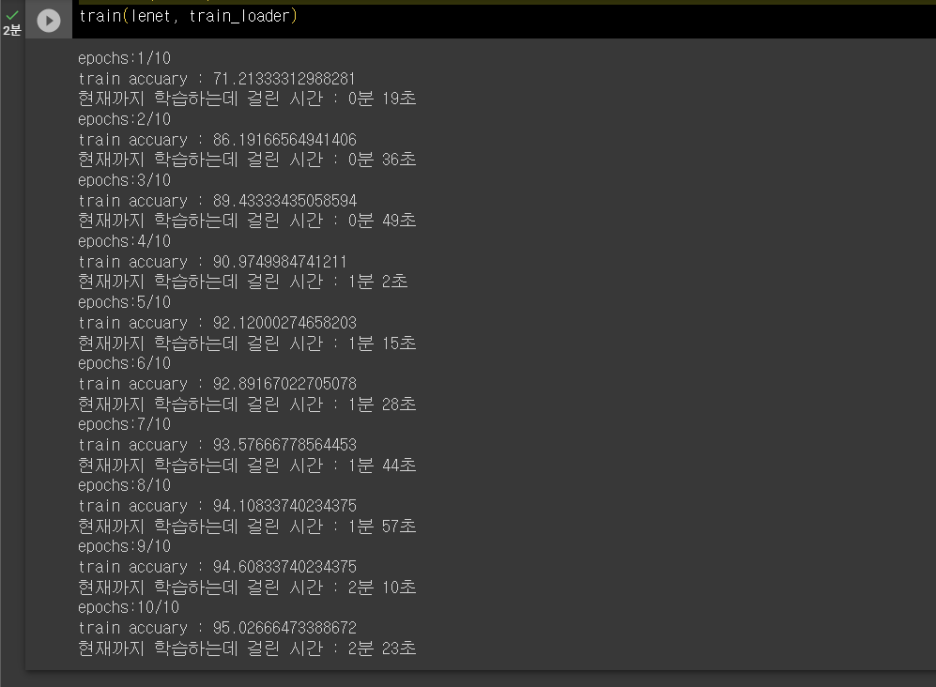
복잡도 검사결과(def 복잡도검사 ) : pooling의 효과로 복잡도가 크게 줄어든 효과를 볼 수 있다!!



AlexNet : ILSVRC 2012에서 1등을 달성한 모델, 이전까지 오류율을 드라마틱하게 줄인 CNN 모델로 딥러닝 재도약기를 이끌었다.
- Convolution layer를 여러개 쌓아서 복잡한 모델 구현 : imagenet(224*224*3)의 데이터를 이용
- GPU에서 모델을 학습 : 역전파 학습시 단순연산에 매우 빠름
- Dropout기법을 처음 적용 : 과적합 방
- 활성화함수로 Sigmoid 대신 ReLU를 처음 적용 : 그래디언트 소실방지 -> 깊은 네트워크에서도 잘 학습

VGG : 3x3의 컨볼루션 필터를 이용한다. ( 7*7의 필터와 3*3*3의 receptive field가 동일하다 )

Resnet : Degradation of accuracy 문제를 해결하여 깊은 신경망(152개)으로도 높은 성능을 달성할 수 있는 모델
* Degradation of accracy : 모델의 층이 증가하고 복잡해짐에 따라서 정확도 감소하는 현상 ( 20layers 부터 )
( gradient 소실, 과적합(overfitting), 데이터 부족 등으로 인해 발생 )
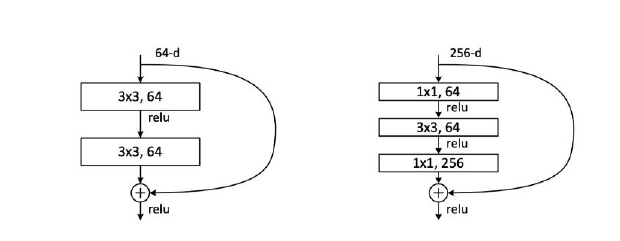
- Residual learning (잔여학습) : 입력 데이터에 변환을 적용한 후, 변환 결과와 원래 입력 데이터를 더하는 방식 => 변환의 차이(잔여)를 학습한다. [ 출력 = 입력 + 잔여 변환(입력) ]
- skip connection(스킵연결 ) : 입력과 동일한 정보를 전달하거나 입력과 다른 레이어로 연결되는 경우, 여러 레이어를 건너뛰어 중간 또는 더 깊은 레이어의 출력으로 직접 연결한다. ( 학습 가중치가 없음, 학습을 수행하지 않음 )

기존 3x3 conv layer 2개 존재하는 구조에서 층을 하나 추가하고 3x3 conv layer 위 아래로 1x1 conv layer를 넣어주는 구조이다.
CIFAR-100 데이터셋 전처리작업
CIFAR-100 : 기계 학습 및 컴퓨터 비전 연구를 위한 고해상도(32x32 픽셀)의 작은 이미지 데이터셋. 100개의 다른 범주(클래스) 당 600개의 이미지가 할당되어 총 60,000개의 이미지로 구성되어 있다.

from torchvision.datasets import CIFAR100
cifar_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(224) #224X224크기로 변환
])
train_dataset3 = CIFAR100('./', transform=cifar_transform, train=True, download=True)
test_dataset3 = CIFAR100('./', transform=cifar_transform, train=False, download=True)기본 32크기를 224로 resize하여 다운로드 한다. 자동으로 학습데이터에 5만개, 테스트데이터에 1만개가 할당된다.
from torch.utils.data import random_split
train_dataset3_1, train_dataset3_2 = random_split(train_dataset3, [10000,40000])
train_loader3 = DataLoader(dataset=train_dataset3_1, batch_size=128, shuffle=True)
test_loader3 = DataLoader(dataset=test_dataset3, batch_size=128, shuffle=True)이때 받은 학습데이터가 5만개이면 너무 많으니 random_split으로 나누어 1만개만 학습하도록 한다.
128개의 데이터씩 미니배치를 생성한다.
전이학습(transfer learning)과 미세조정(fine tuning)
* 전이학습(transfer learning) : 같은 문제를 해결하는데 사용했던 네트워크를 다른 데이터셋과 다른 문제에 적용시켜서 푸는 방식
=> 이미지에서 특징(feature)을 추출하는 네트워크 부분 (=백본, backbone)을 가져와서 이용한다.
=> 이는 잘 수행된 모델의 일부이기에 모델전체 학습시에 학습하지 않는다.
주로 object detection모델에서 이를 이용한다.
대표적인 예시의 FPN(Fully Convolutional Pyramid Network: 객체 감지와 시맨틱 분할 작업을 위한 딥러닝 모델 아키텍처 )의 구조이다. IMAGENET으로 학습한 ResNet 네트워크부분을 백본으로 작업을 수행한다.

- torchvision.models : 아키텍처와 미리 학습된(pre-trained) 가중치를 가진 모델들을 포함하는 모듈
- models.resnet34(pretrained = True) : torchvision 라이브러리에서 제공하는 ResNet-34 모델을 생성 (ImageNet 데이터셋에서 학습된 가중치를 포함)
- 파라미터.requires_grad = False : 모델의 파라미터(가중치)를 동결하여 학습을 방지한다.
from torchvision import models
resnet34_pretrained = models.resnet34(pretrained=True)
#백본의 모든 param을 가져와서 학습을 멈춤(freeze)
for param in resnet34_pretrained.parameters():
param.requires_grad = False
#마지막 fc레이어 : 이미지넷 데이터셋에서 1000개의 클래스로 분류 -> cifar의 100개 클래스로 조정
resnet34_pretrained.fc = nn.Sequential(
nn.Linear (in_features=512, out_features=100),
nn.Softmax()
)마지막 fc레이어에서 out_features값을 수정한다. ( 이미지넷에서 1000개 클래스 -> cifar에서 100개 클래스 )
이때 in_features는 그대로 고정한다.


파라미터를 freeze + FCL의 출력피처값을 바꾼 전과후의 torchsummary확인 결과차이
trainable params의 갯수가 확연하게 줄었고, non-trainable params의 갯수가 크게 발생했다.

* 미세조정(fine tuning) : 전이학습처럼 이미 학습된 모델을 가지고 와서 사용하지만 모델 전체를 다시 학습시킨다.
=> 모델의 모든 가중치가 학습되기에 빠르게 성능이 좋아지고 적은 데이터로 좋은 성능을 낼 수 있다.
ex. 일반적인 Classification에서 마지막 FC Layer(MLP)만 바꿔서 개랑 고양이 구별기로 바꾸도록 한다.
resnet34_pretrained2 = models.resnet34(pretrained=True)
#FC를 변경하는 작업
resnet34_pretrained2.fc = nn.Sequential(
nn.Linear(in_features=512, out_features=100),
nn.Softmax()
)fine tuning으로 적용하기 위해 resnet34를 다시 불러온다.
이때는 모든 파라미터를 학습하기 위해 freeze하지 않고 FC만 변경해준다.

학습의 결과이다(GPU이용) :: 미세조정의 결과 순전파시간(forward)는 오래걸리지만 accuracy 성능이 확연히 좋아졌다.

'machine learning & deep learning' 카테고리의 다른 글
| [프로젝트 회고] PytorchLightning기반 딥러닝 프로젝트 - 데이터전처리 (0) | 2024.07.19 |
|---|---|
| RNN(순환신경망), LSTM(장단기메모리) 실습 : 주가분석, 영화리뷰분석 (0) | 2024.03.10 |
| Computer vision에서의 딥러닝 : OpenCV & U-net (0) | 2024.03.10 |
| 머신러닝 기초 & MLP 인공신경망 (0) | 2024.03.10 |