23.10.15
시계열 데이터(sequence data)
: 시간에 따라 생성되는 순서가 있는 데이터 ( ex. 영상데이터, 음성데이터, 문자열 데이터 등.. )
이전데이터가 현재데이터여 영향을 미치는 관계성을 가진다.
이는 시간축 신경망 모델(time serires model)을 이용하여 분석하고 예측한다. ( ex. RNN, LSTM, transformer )
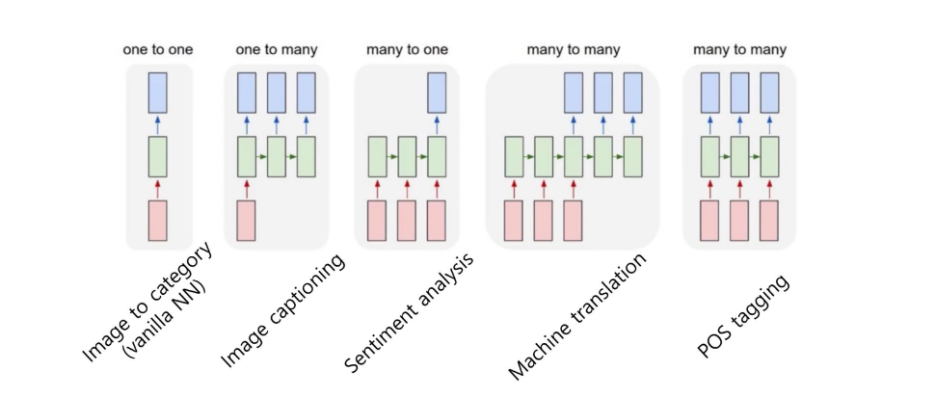
RNN( Recurrent Neural Network) : 순환신경망 모델
이전 단계의 출력(hidden state : ht)을 현재 단계의 입력(input : xt)과 함께 사용하여 학습(output : yt)하는 모델
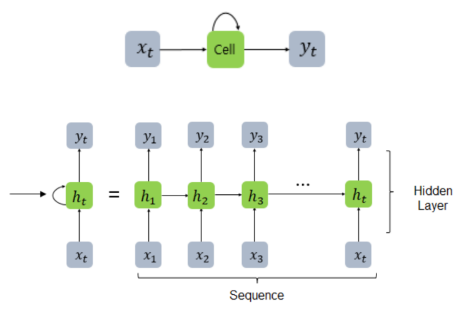
RNN모델에서 hidden layer(=메모리셀)는 이전, 현재 정보를 모두 weight sum 하여 압축하고 활성화시킨다 ( 주로 하이퍼볼릭 탄센트( tanh 이용) )
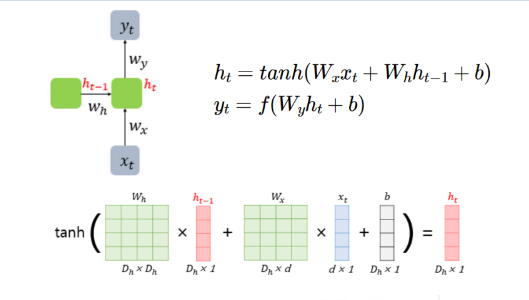
같은 시간단계(step)에서 한방향의 weight는 시간타이밍과 관계없이 동일 한 값으로 BP(역전파) 시에 업데이트 된다. ( = 가중치공유)
이전벡터의 크기 = Dh , 입력벡터의 크기 = d / Wx는 Dh*d 로 설계됨 -> 이전 벡터크기와 동일한 크기(Dh)로 맞추어진다.
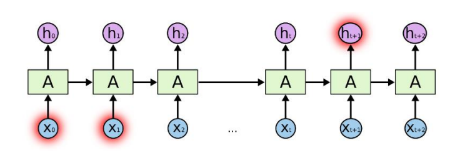
이러한 RNN의 가장 큰 한계점은 장기의존성문제(The problem of Long-term Dependencies) 이다.
분석 시퀀스가 길어질수록 이전정보의 보존성이 낮아진다는 것이다.( =시퀀스 의존성이 낮아짐 )
또 시퀀스가 길어질수록 순환구조로 인한 gradient 소실 혹은 폭발, 고정윈도우크기만 기억하는 문제점이 발생할 수 있다.
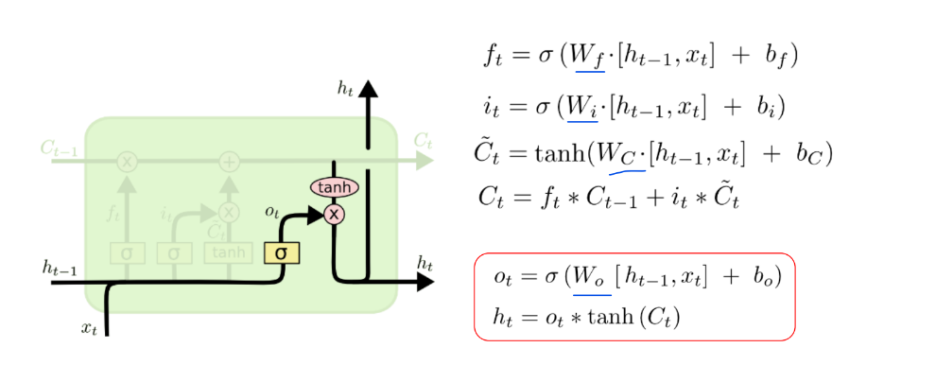
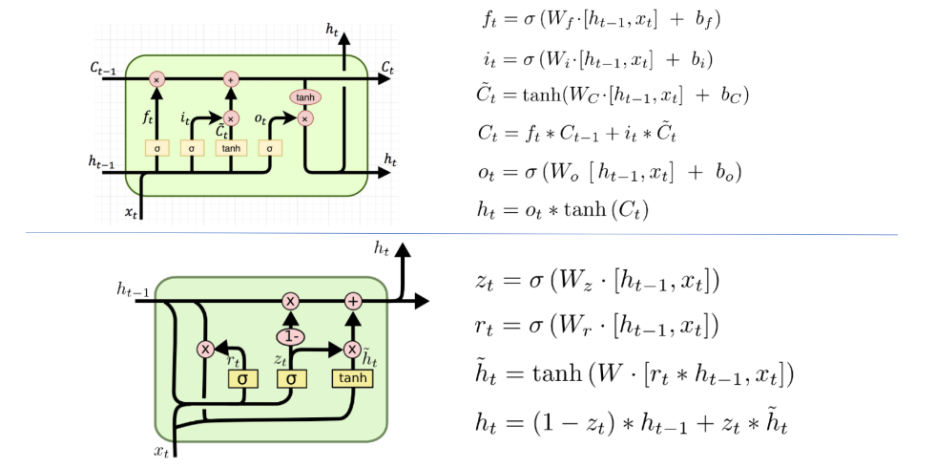
LSTM( long time term memory ) : 장단기메모리 신경망
RNN의 변형아키텍처로 장기의존성문제를 해결하기 위해 셀상태 & 게이트 매커니즘을 도입했다. ( 3개의 gate와 1개의 state )
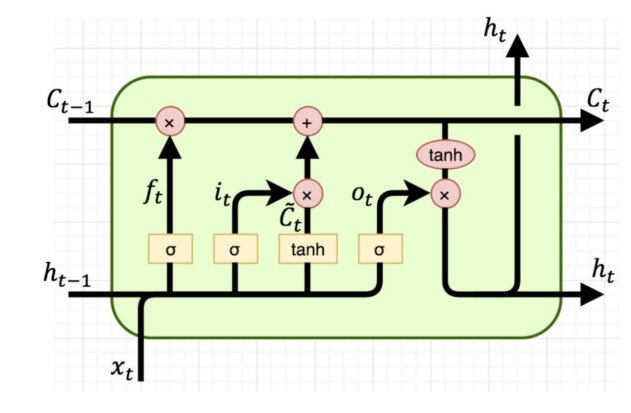
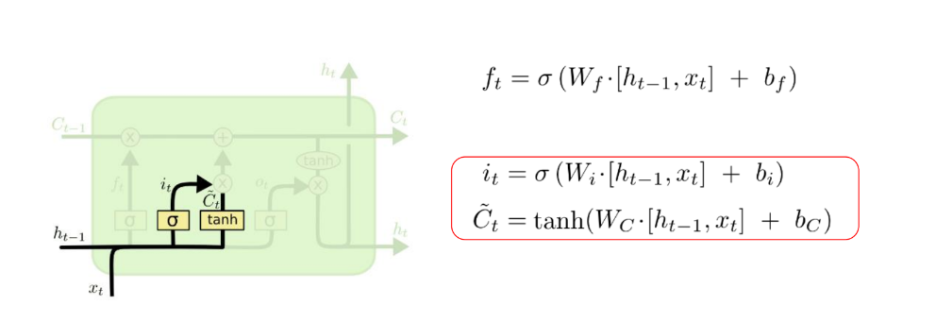
Input gate(i) : 정보( input정보와 hidden정보의 합산연결 )중 어떤 것을 입력할지 결정한다. ( 0~1 사이의 중요도 )
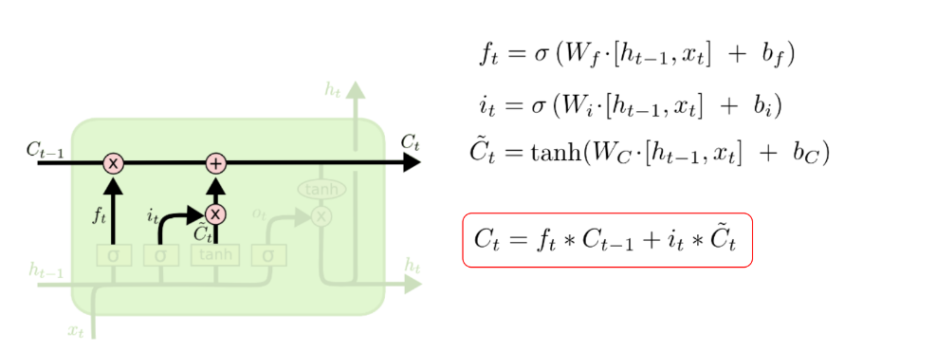
Cell state(c) : 메모리셀의 역할로 장기의존성정보를 저장하고 전달
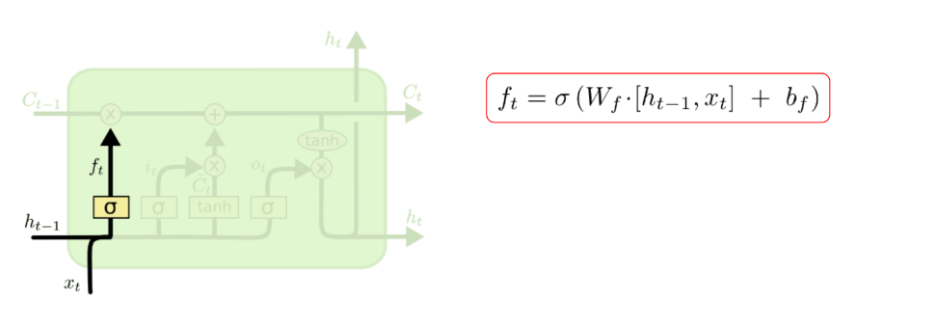
- 시간단계마다 update( ft, fi를 반영하여 입력, 수정, 삭제 ) : 기존정보의 유지정도(f) + 새정보의 입력정도(i)
Output gate(o) : 어떤정보를 다음 은닉층으로 전달할지 결정한다. ( 0~1 사이의 중요도 ) -> 전달정보 ht가 새롭게 생성된다.
유사한 모델로 GRU(쾌적한 순환 유닛, Gated Recurrent Unit)이 존재한다.
LSTM보다 게이트 수를 줄이면서 성능을 보장하는 모델이다.
LSTM을 이용한 삼성전자 주가분석
1. 주가 데이터 불러오기
pandas.read_csv : CSV (Comma-Separated Values) 파일에서 데이터를 읽어와 데이터프레임(DataFrame)을 생성
## idex_col : 데이터 프레임에서 해당 열을 인덱스(각 행을 고유하게 식별하는 역할)로 지정
# pandas를 이용해서 csv 파일을 읽어오기
import pandas as pd
df = pd.read_csv(os.path.join(root_dir, 'samsung_cospi.csv'), index_col='Date')
df.head(5) #최상단 5개출력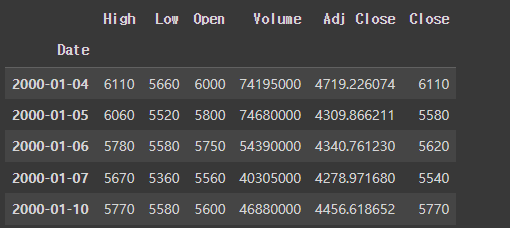
2-1. 학습준비 : 데이터 처리
입력데이터X와 이에 대한 정답데이터y를 생성
pandas.DataFrame.drop() : 데이터프레임에서 지정된 행 또는 열을 삭제
pandas.DataFrame.iloc[행, 열] : 데이터프레임(DataFrame)에서 행(row)과 열(column)을 정수 기반의 위치로 선택하는 pd메서드
X = df.drop(columns='Adj Close') #target값(Adj Close)을 제외한 입력값 -> 나머지 5개 feature
y = df.iloc[:, 4:5] #taraget값(Adj Close)이 있는 4열을 slicing -> 1개 feature
print(X, y, sep='\n\n')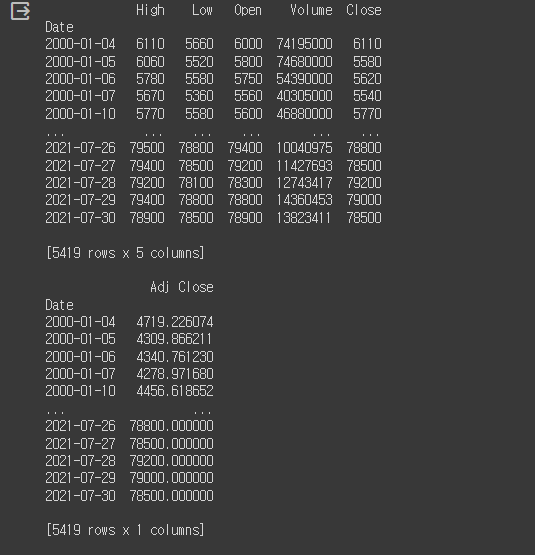
*정규화
이때 주식 데이터가 서로다른 단위의 feature로 구성되어있는 특징을 볼 수 있다.
[ high, low, open, close -> 가격값(원) / volume -> 수량(천만개) ]
정규화 작업(스케일링)을 통해 상이한 데이터 단위를 일치시켜줘야한다. 그렇지 않으면 단위가 큰 volume값에 민감하게 반응하게 된다..
sklearn.preprocessing.MinMaxScaler : 데이터를 특정 범위 내(0~1)로 조정한다 -> 0(최소값) ~ 1(최대값) 으로 매핑
=> MMS객체.fit_transform(데이터)
!pip install scikit-learn==1.2.2
from sklearn.preprocessing import MinMaxScaler
#MinMaxScaler객체 2개 생성
mm = MinMaxScaler()
ss = MinMaxScaler()
# mm을 통해 y(output)을 scaling
y_mm = mm.fit_transform(y)
y_mm
# mm을 통해 X(input)을 scaling
X_ss = ss.fit_transform(X)
X_ss
*데이터셋 분리
# X_train: 학습데이터 + y_train : 학습데이터 정답 ( 4800개 )
# X_test : 테스트데이터 + y_test : 테스트데이터 정답( 이후 )
X_train = X_ss[:4800, :]
X_test = X_ss[4800:, :]
y_train = y_mm[:4800, :]
y_test = y_mm[4800:, :]
데이터들을 RNN의 input, output 텐서형태( Xt : batch_size, 1 , input_size )로 변환해야한다.
- batch_size : 한번에 처리할 데이터의 양 (행)
- n : (1) 각 데이터포인트의 시간단계 ( timestep ), 시계열 데이터의 길이 ( sequence_length ) => inputs, outputs (2) 순환 레이어의 갯수( num_layers ), 총 recurrent의 횟수 => hidden, cell => 1이라면 한 단계( 하나의 layer, recurrent, timestep )을 의미한다. 생략가능
- input_size, hidden_size : feature의 수 (열)
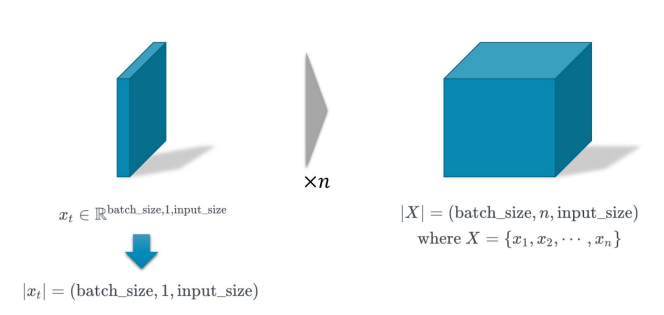
xt = 하나의 timestep에서의 입력
X = bs * is 의 데이터를 n시간(번)만큼 입력받는다.
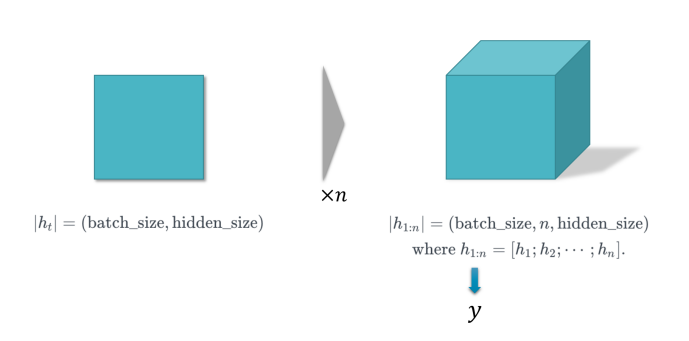
ht = 하나의 출력 ( sequential 하지 않은 출력)
h1:n = bs*hs의 데이터를 n시간(번)만큼 출력한다.
다차원배열로 얻은 데이터 -> pytorch 텐서 -> RNN 텐서 순서로 변환해준다.
torch.FloatTensor: 실수(float) 데이터를 가지는 PyTorch 텐서를 생성
#입력데이터(X) : ( bs, 1, is )의 형태로 변환 : reshape(4800, 1, 5) / reshape(619, 1, 1)
#X_train = torch.FloatTensor(X_train).reshape(X_train.shape[0], 1, X_train.shape[1])
#X_test = torch.FloatTensor(X_test).reshape(X_test.shape[0], 1, X_test.shape[1])
X_train = torch.FloatTensor(X_train).reshape(X_train.shape[0], 1, 5)
X_test = torch.FloatTensor(X_test).reshape(X_test.shape[0], 1, 5)
#정답데이터(y) : ( bs, 1, hs )의 형태로 변환 : sqential 하지 않음 -> RNN 텐서형식을 따를필요없음 / 텐서로만 변환
y_train = torch.FloatTensor(y_train)
y_test = torch.FloatTensor(y_test)
2-2. 학습준비 : 모델설계
다양한 하이퍼파라미터 설정 ( = 사전설정 : model training configuration)을 수행
n_epochs = 5000 #에폭수 : 전체데이터를 학습하는 횟수
learning_rate = 0.001 #loss에 따라 parameter를 업데이트하는 정도
input_size = 5 # feature 수
hidden_size = 2 # linear layer를 통과하여 1이 된다.(outputsize)
num_layers = 1 # LSTM layer의 수 = recurrent 수
num_classes = 1 # 예측값의 수 = hidden_size가 결국 도출되어야하는 값
설계한 Model의 구조 = LSTM 층 1개 + FCL층 2개
- torch.nn.LSTM() : PyTorch에서 제공하는 LSTM모델 클래스 -> 하이퍼파라미터만 설정해주면 알아서 hidden state와 cell state를 구성하여 작동한다.
- torch.nn.Linear() : PyTorch에서 제공하는 선형레이어를 나타내는 클래스 -> in_features(입력특성), out_features(출력특성)만 지정해주면 알아서 weight를 구성하고 학습해준다. ( 벡터화하여 변환, 값유지 )
( :: hidden size의 결과물 -> 128차원 벡터 -> class size(1차원 벡터)(prediction 값)로 변환 )
torch.view() : 배열(tensor)의 형상(shape)을 변경하거나 조작 ( 원본 텐서와 메모리를 공유 -> 같은 메모리 위치를 참조, 변경영향 )
torch.reshape() : 원본 텐서와 메모리를 공유하지 않고 메모리공간 새로 할당 ( 변경에 영향x)
#모델정의
class Model(nn.Module):
def __init__(self, input_size, hidden_size, num_classes, num_layers, seq_length):
#1. 초기화 작업
self.input_size = input_size
self.hidden_size = hidden_size
self.num_classes = num_classes
self.num_layers = num_layers
self.seq_length = seq_length
super(Model, self).__init__()
#LSTM 객체 정의 : 만들어진 내부구조에 is, hs, num_layers등만 결정한다..
self.lstm = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True #(bs,1,is)형태
)
#FCL구성 : 2개
#nn.Linear
self.fc_1 = nn.Linear(hidden_size, 128) #2차원벡터 -> 128차원벡터
self.fc = nn.Linear(128, num_classes) #128차원벡터 -> 1차원벡터(=output=prediction)
self.relu = nn.ReLU()
#2. forward pass
def forward(self,x):
output, (hn, cn) = self.lstm(x)
#입력값을lstm구현함수에 통과시킨다. -> 내부적으로 output, hn, cn도출
#output.shape : [48000, 1, 2]
#hn.shape : [1, 48000, 2]
#cn.shape : [1, 48000, 2]
#사실상 hn, output은 데이터형태만 다를뿐 내용은 똑같다
hn = hn.view( -1, self.hidden_size ) #(48000,2)
out = self.relu(hn) #(48000,2)
out = self.fc_1(out) #(48000,128)
out = self.relu(out) #형상유지
out = self.fc(out) #(48000,1) : 48000개의 prediction값들
return out
학습을 위한 loss함수, optimizer 구축
nn.MSELoss() : PyTorch에서 제공하는 평균 제곱 오차(Mean Squared Error, MSE) 손실 함수
torch.optim.Adam() : PyTorch에서 제공하는 Adam(Adaptive Moment Estimation) 최적화 알고리즘 : 경사 하강법으로 신경망학습
## model.parameters() : 모델에서 학습할 모든 파라미터 전달
## lr = learning_rate : 학습정도를 결정하는 학습률 전달
model= Model(input_size, hidden_size, num_classes, num_layers, seq_length=X_train.shape[1])
loss_function = nn.MSELoss() #MSELoss함수 이용
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
3. 모델학습
배치사이즈가 곧 전체사이즈(48000) => 전체데이터의 로테이션( epoch )마다 학습을 진행한다.
optimizer.zero_grad() : 모델의 그래디언트(gradient)를 초기화(0) -> 이전 반복에서의 그래디언트 값이 누적되지 않도록 함
loss.backward() : loss함수에서 도출된 결과로 gradient를 계산
optimizer.step() : 계산된 gradient를 바탕으로 가중치 업데이트 진행
for epoch in range(n_epochs):
#에폭수(5000)만큼 전체 데이터 로테이션돌림 => 4800개(배치이자 전체데이터)의 데이터를 5000번 학습한다.
outputs = model(X_train.to(device))
optimizer.zero_grad() #매 에폭마다 optimizer 초기화
# backward pass : loss값 역시 gpu로 보낸다.
loss = loss_function(outputs, y_train.to(device))
loss.backward() #gradient 계산
optimizer.step() #옵티마이저로 가중치 업데이트
if epoch % 100 == 0: #에폭단위 100마다 loss값을 확인해본다.(=training loss)
print("Epoch : %d, loss : %.5f" % (epoch, loss.item()))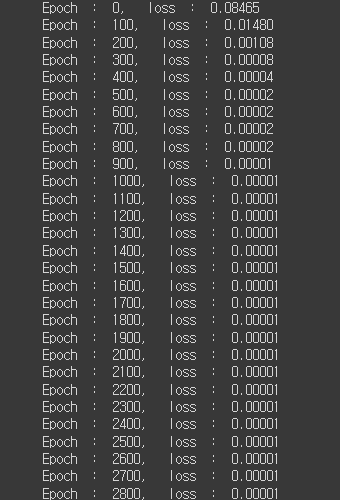
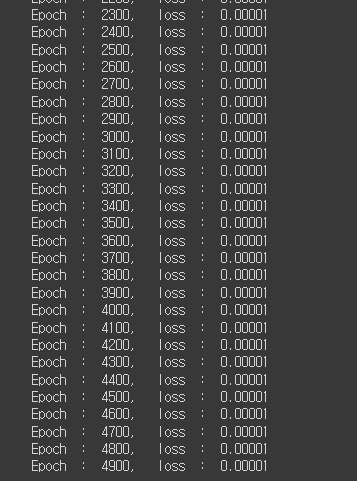
5000번의 학습결과 -> 초기 8%였던 손실률 0.001%까지 내려가는 것을 확인할 수 있다..
4. 테스트 확인
마지막까지 학습한 모델을 가지고 테스트 추론을 시작한다.
연산으로 인해 GPU에 저장된 값을 CPU로 가져와서 시각화하고자 한다.
역정규화했던 모든 값들중 예측값(adj close)만 원래의 scale로 역정규화하여 확인한다. ( 정규화이전의 값을 담고 있는 MMS객체 이용)
MMS객체.inverse_transform(대상) : 사이킷런에서 데이터 전처리 후 모델의 예측값을 원래 스케일이나 형태로 복원하는 데 사용
prediction = model(X_test.to(device)) #test데이터를 가지고 예측진행
prediction = prediction.data.detach().cpu().numpy() #gpu에 위치한 prediction값을 cpu로 가져온다. -> np배열화
#역정규화 : 예측값(adj close)을 원래의 scale로 돌려서 결과를 확인할 것이다!
prediction = mm.inverse_transform(prediction) #예측결과 역정규화
y_test = mm.inverse_transform(y_test) #정답값 역정규화
plt.figure(figsize=(10, 6))
plt.plot(y_test, label='Actual Data')
plt.plot(prediction, label='Predicted Data')
plt.title('Time-Series Prediction')
plt.legend(loc='upper left')
plt.show()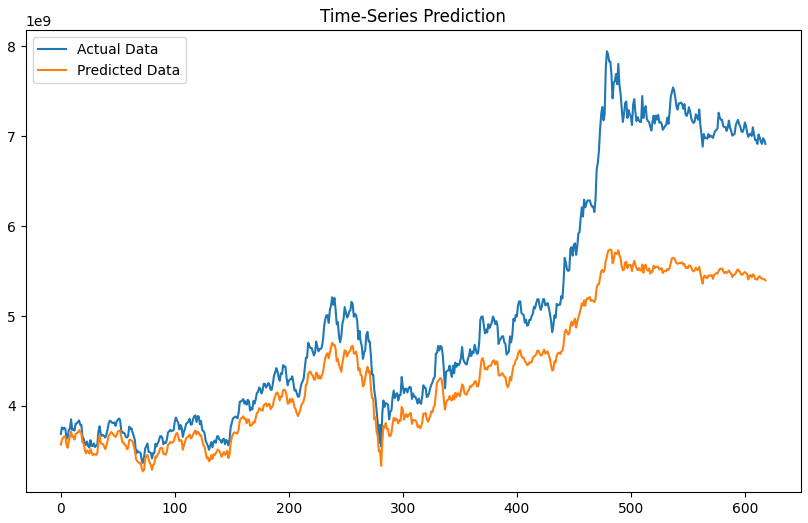
LSTM을 이용한 영화리뷰 분석
0. TorchText 설치 & IMDB 데이터셋 다운로드 및 전처리
: Pytorch에서 자연어 처리(Natural Language Processing, NLP) 작업을 위한 데이터셋 처리작업 라이브러리
( 텍스트 데이터를 로드하고 전처리하는 데 사용 )
!pip install torchtext==0.6.0
torchtext.data.Field() : 텍스트 데이터를 어떻게 처리할지 정의하는 클래스-> 토큰화 및 전처리 방법 지정, vocabulary 지정 등..
# sequential : 시퀀스 데이터 여부 (default: True)
# use_vocab : 단어 집합(vocabulary)을 만들 것인가 (default: True)
# lower : 영어 데이터를 전부 소문자화 (default: False)
# batch_first : 미니 배치 차원을 맨 앞으로 할 것인가 (default: False)
# fix_length : 최대 허용 길이. 이 길이에 맞춰서 패딩 (길이의 일관성)
IMDB 데이터셋 : 텍스트 분류(text classification) 연습용 데이터셋 (영화 리뷰 데이터)
-- torchtext.datasets.IMDB = 리뷰 텍스트("text" 키) + 리뷰의 긍정(1) 또는 부정(0) 레이블("label" 키)
vars() : 대상을 딕셔너리 형태로 반환 (주어진 객체의 __dict__ 속성을 반환)
fields 속성 : 데이터셋의 각 열(column), 해당 열의 데이터를 어떻게 처리할지를 정의
items() : 속성을 딕셔너리 형태로 반환
from torchtext import data, datasets
import torch.nn as nn
import torch
TEXT = data.Field(sequential=True, batch_first=True, lower=True) #문장데이터 형식담을 객체(리뷰)
LABEL = data.Field(sequential=False, batch_first=True) #정답데이터 형식담을 객체(good/bad)
#IMDB데이터셋을 지정한 TEXT와 LABEL에 맞게 trainset, testset으로 나누어준다.
trainset, testset = datasets.IMDB.splits(TEXT, LABEL)
print(vars(trainset[0]))
print(trainset.fields.items()){'text': ['allison', "dean's", 'performance', 'is', 'what', 'stands', 'out', 'in', 'my', 'mind', 'watching', 'this', 'film.', 'she', 'balances', 'out', 'the', 'melancholy', 'tone', 'of', 'the', 'film', 'with', 'an', 'iridescent', 'energy.', 'i', 'would', 'like', 'to', 'see', 'more', 'of', 'her.'],
'label': 'pos'}
dict_items([('text', <torchtext.data.field.Field object at 0x7bff1397be20>), ('label', <torchtext.data.field.Field object at 0x7bff13978c40>)])
*단어 집합(Vocabulary) 생성
Field 클래스 객체.build_vocab() : Field 클래스로 정의한 객체에 대해서 vocab(단어 사전)를 구축하는 데 사용
# min_freq = 최소 등장단어수 -> 이 이상등장하는 것들로 vocab을 생성
# max_size = 단어집합의 크기제한
# 이때 2개의 모든 단어집합에는 special token이 저장 <unk> <pad>
단어집합.stoi : vocab의 인덱스 = 해당 글자의 one-hot incoding된 위치를 말한다. ('<unk>' 0번째 , '<pad>' 1번째)
TEXT.build_vocab(trainset, min_freq=10, max_size=10000)
print("단어 집합(Vocabulary) 크기: ", len(TEXT.vocab))
print(TEXT.vocab.stoi)
1-1. 학습준비 - 데이터 처리
*데이터셋 구축
기존 train data를 한번더 나누어서 validation data를 만들고자 한다.
▶ validation data : 모델의 성능을 평가하고 조정하기 위해 사용 ( 학습데이터와는 별도의 것으로, 학습의 대상이 아님)
배치를 사용하여 모델을 학습하고 업데이트한 다음, 해당 배치에 대한 모델의 파라미터(가중치 및 편향)를 사용하여 검증 데이터를 평가
(= 개별 배치의 update를 평가하는 검증용 데이터 -> training loss보다 더 유의미한 validation loss를 도출 )
#trainingset을 한번더 split한다 -> train용(80%)과 validation용(20%)으로 구분하고자 한다.
trainset, validset = trainset.split(split_ratio=0.8)▶ 배치화(batchify) : 학습할 때 사용되는 데이터를 작은 묶음 또는 배치로 나누는 과정, 이는 trainset에서 랜덤하게 선별(shuffle) -> 과적합 방지 / 에폭은 여러 미니배치들로 구성되어있으며 여러번 update가 발생할 수 있다
torchtext.data.BucketIterator.splits : 데이터셋을 미니배치로 나누고 배치를 생성, 주로 텍스트 데이터를 다룬다.
훈련 데이터, 검증 데이터, 테스트 데이터를 지정한 batch_size로 나눈다. -> 각 부분은 데이터의 크기에 따라 유사한 크기의 배치로 그룹화
next(iter(배치의 그룹)) : 하나의 배치를 추출
batch_size = 64
learning_rate = 1e-3 #0.001
n_epochs = 10 #전제 데이터 반복횟수
train_iter, val_iter, test_iter = data.BucketIterator.splits(
(trainset, validset, testset), batch_size=batch_size, shuffle=True, repeat=False
)
mini_batch = next(iter(train_iter))
print(mini_batch)
print(mini_batch.text.shape)
print(mini_batch.text)[torchtext.data.batch.Batch of size 64]
[.text]:[torch.LongTensor of size 64x957]
[.label]:[torch.LongTensor of size 64]
torch.Size([64, 957])
tensor([[ 5, 532, 27, ..., 1, 1, 1],
[ 94, 296, 2, ..., 1, 1, 1],
[ 2, 20, 14, ..., 1, 1, 1],
...,
[ 82, 5, 364, ..., 1, 1, 1],
[ 30, 5, 57, ..., 1, 1, 1],
[ 225, 19167, 0, ..., 1, 1, 1]])배치구조 : 텍스트데이터 + 이에 대한 정답데이터
텍스트데이터, 정답데이터구조 : 각 단어가 vocab번호로 배치 & 배치내의 최대크기 문장(801)에 맞추어서 pad(1)이 채워져있다.
1-2. 학습준비 : 모델설계
설계한 Model의 구조 = 임베딩층 + LSTM층(n_layers개) + FCL층 1개 + dropout
- torch.nn.Embedding(vocab,embed ) : 자연어 처리 (NLP)에서 고유인덱스에 해당하는 고정 차원의 벡터(embedding vector)를 반환
- torch.nn.LSTM
# input_size : 입력 특성차원
# hidden_size : 은닉(출력) 특성차원
# num_layers
# batch_first=batch_first
- torch.nn.Linear ( :: hidden size의 결과물을 class size(2차원 벡터)로 변환 )
- torch.nn.Dropout(p) : p의 확률만큼 dropout 진행
▶ 임베딩(Embedding) : voacb_size(입력텐서의 input_size)의 문자열데이터를(원핫인코딩) 지정한 embed_size만큼으로 축소(열축소)
vs를 es로 선형변환하는 것
class Model(nn.Module):
def __init__(self, n_layers, hidden_dim, n_vocab, embed_dim, n_classes, dropout_p=0.2):
self.n_layers = n_layers
self.hidden_dim = hidden_dim
super(Model, self).__init__()
self.embed = nn.Embedding(n_vocab, embed_dim) #input size(vocab size) -> embed size로 축소
self.lstm = nn.LSTM(embed_dim, self.hidden_dim, num_layers=self.n_layers, batch_first=True)
#LSTM에 들어가는 것은 축소변환된 embed_dim이 된다!!
self.out = nn.Linear(self.hidden_dim, n_classes) #도출되는 hidden size를 -> 최종 2개의 클래스
self.dropout = nn.Dropout(dropout_p)
def forward(self, x): #(bs,1,vs)
x = self.embed(x)
output, (hn, cn) = self.lstm(x) #(bs,1,es)
hn = hn[1] #마지막 시점의 hn = (bs, hs) : sequential하지 않음
hn = self.dropout(hn)
logit = self.out(hn) #linear처리 -> 길이가 2인 벡터(각 pos, neg에 대한 확률값)
return logit2. 모델학습(train)
- train 함수 : train_iter(train 배치그룹)을 받아 학습처리
- evaluate 함수 : valid_iter(valid 배치그룹)을 받아 갱신한 가중치의 모델을 검증처리
각 배치에서의 손실, 정답의 합을 구함 -> 평균손실, 평균정확도를 만든다.
**이때 IMDB 데이터셋의 label 데이터(y)는 {1,2}로 구분된 상태이므로 1을 빼서 {0,1}로 만듬
* 모델 학습의 기본 순서(6단계) *
(1) 모델객체.train() : 훈련모드로 전환
(2) optimizer.zero_grad() : 이전 반복의 gradient 계산을 초기화
(3) forward 연산 ( 보통 model(데이터) )
(4) loss 계산 ( 보통 loss = 사용할 loss함수(출력값, 정답) )
(5) backward 연산 = gradient의 계산 ( loss.backward() )
(6) 가중치 갱신(update) ( optimizer.step() )
F.cross_entropy( input, target ) : 분류 문제의 손실을 계산하는 데 사용되며, 모델의 예측과 실제 타겟 간의 차이를 측정
# reduction='sum' : eval모드에서 선택하는 옵션 / 정규화, 일관성, 학습률 조절을 위한 선택
torch.item() : PyTorch 텐서의 값을 스칼라로 변환하는 메서드 (손실함수에서 계산한 loss는 pytorch텐서형태 )
def train(model, optimizer, train_iter):
model.train() #학습모드
for _, mini_batch in enumerate(train_iter):
#iter을 반복적으로 추출 => 인덱스, 미니배치데이터(text, label)
#x, y = mini_batch.text.to(device), mini_batch.label.to(device)
x, y = mini_batch.text, mini_batch.label
y.data.sub_(1)
#y 데이터가 1,2로 구분된 상태
#1을 빼서 0 과 1로 변환 : 1 -> 0 2 -> 1
optimizer.zero_grad() #optim초기화
logit = model(x) #forward
loss = F.cross_entropy(logit, y) #cross entropy loss 함수로 loss 반환
#cross entropy :정답(y) value가 1인 인덱스끼리의 확률차이를 비교 = loss
loss.backward() #backward
optimizer.step() #update
def evaluate(model, val_iter): #update작업을 하지 않기에 optimizer 필요X
model.eval() #평가모드
corrects, total_loss = 0, 0 #맞힌갯수, 전체 loss
for mini_batch in val_iter:
#x, y = mini_batch.text.to(device), mini_batch.label.to(device)
x, y = mini_batch.text, mini_batch.label
y.data.sub_(1)
logit = model(x)
loss = F.cross_entropy(logit, y, reduction='sum')
#배치에서 수행되는 loss를 모두 더함 / 배치마다의 손실을 합산한 전체 손실
# reduction='sum'-> 정규화, 일관성, 학습률 조절을 위한 선택
total_loss += loss.item()
#item() : PyTorch 텐서의 값을 스칼라로 변환하는 메서드 (텐서 형태의 손실 값을 숫자로 변환)
corrects += (logit.max(1)[1].view(y.size()).data == y.data).sum()
#높은 확률로 예측한 것 정답
# 평균손실 : 전체loss/미니배치수(iter가 돌아간 횟수)
avg_loss = total_loss / len(val_iter.dataset)
# 평균정확도 : 전체 맞춘수/미니배치수(iter가 돌아간 횟수)
avg_accuracy = 100.0 * corrects / len(val_iter.dataset)
return avg_loss, avg_accuracymodel에 하이퍼파라미터 값을 설정
optimizer에 model의 모든 파라미터를 학습대상으로 설정
epoch(1) : train( 내부배치들에서 update ) -> 모델 evaluate
이때 에폭별 모델마다 loss값을 비교해서 최적의 모델을 save한다.
model.state_dict(): model 객체의 상태사전(state dictionary)을 반환 (가중치(weight)와 편향(bias) 등의 매개변수의 내용)
torch.save(): PyTorch의 저장 함수, 첫번째 객체를 두번째 경로에 저장
#모델 설정 : lstm layer 2개 / vocab_size를 embed사이즈(400)로 변환 / 256의 hiddensize를 2로 변환 / drop =0.5
model = Model(2, 256, vocab_size, 400, n_classes, 0.5)
# optimizer 설정
optimizer =torch. optim.Adam(model.parameters(), lr=learning_rate)
best_val_loss = None #최소 손실값
for e in range(1, n_epochs+1):
train(model, optimizer, train_iter) #한번의 에폭 train -> 내부 배치들만큼 update
val_loss, val_accuracy = evaluate(model, val_iter) #한번의 train이후 validate하여 평균손실, 평균정확도 구함
#에폭에 해당하는 평균손실, 평균정확도를 구함
print("Epoch: %d | Val loss: %.2f | Val accuracy: %.2f" % (e, val_loss, val_accuracy))
#bvl은 가장 작은 값으로 지속적으로 update
if not best_val_loss or val_loss < best_val_loss:
torch.save(model.state_dict(), './txtclassification.pt') #모델의 현재상태를 가져와서 해당위치에 저장하고
best_val_loss = val_loss #bvl을 현재 loss로 갱신
print(best_val_loss) #모델의 최종적인 loss값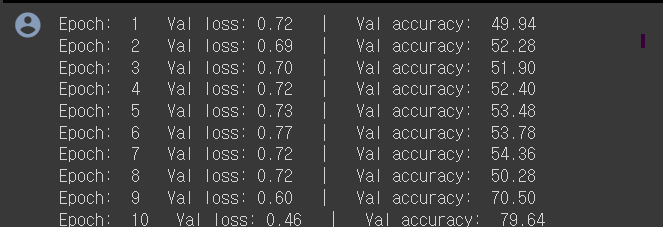
epoch이 반복될수록 loss는 작아지고 accuracy는 증가한다..!!!!
3. 모델검증(test)
최적의 모델을 load해온다 -> train_iter을 가지고 검증한다 ( evaluate 함수 재사용 : 배치별로 loss, accuracy를 구해 평균을 계산 )
model.load_state_dict(torch.load('./txtclassification.pt'))
test_loss, test_acc = evaluate(model, test_iter)
print("테스트 오차: %5.2f | 테스트 정확도: %5.2f" % (test_loss, test_acc))테스트 오차: 0.58 | 테스트 정확도: 76.29테스트 배치들로 검증해본 결과가 된다!
'machine learning & deep learning' 카테고리의 다른 글
| [프로젝트 회고] PytorchLightning기반 딥러닝 프로젝트 - 데이터전처리 (0) | 2024.07.19 |
|---|---|
| Computer vision에서의 딥러닝 : OpenCV & U-net (0) | 2024.03.10 |
| 합성곱신경망 : CNN(conventional Neural Network) (0) | 2024.03.10 |
| 머신러닝 기초 & MLP 인공신경망 (0) | 2024.03.10 |