23.10.02
Computer vision이란?
컴퓨터에게 시각데이터(visioin)처리 능력을 부여하는 컴퓨터 공학의 한 분야이다.
AlexNet이 ILSVRC에서 큰 성과를 내면서 딥러닝이 computer vision task에 크게 활용되기 시작했다.
색 공간(color space)
:: 컴퓨터 비전, 이미지 처리 작업에서 색상을 표현하고 다루는 방법을 정의하는 수학적 모델이나 체계
이미지의 픽셀에서 색상 정보를 추출하거나 조작할 때 사용한다.
- Grayscale : 각 픽셀의 색상 정보가 없고(흑백 이미지) 명암(밝기) 정보만을 포함 => 단일채널로 밝기표현
- RGB : 빨강 (Red), 녹색 (Green), 파랑 (Blue)의 3개의 색상 채널을 사용하여 픽셀의 색상표현
- HSV : 색상 (Hue), 채도 (Saturation), 명도 (Value) 세 가지 요소로 색상표현
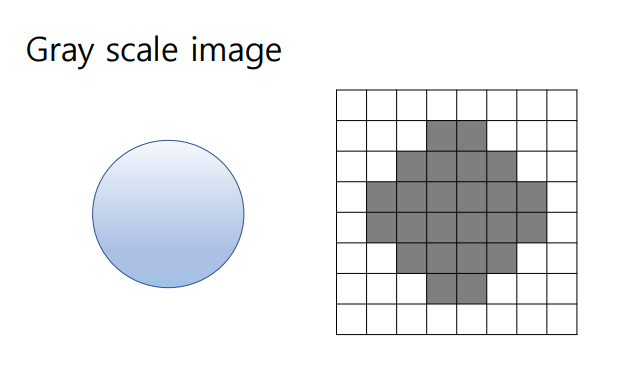
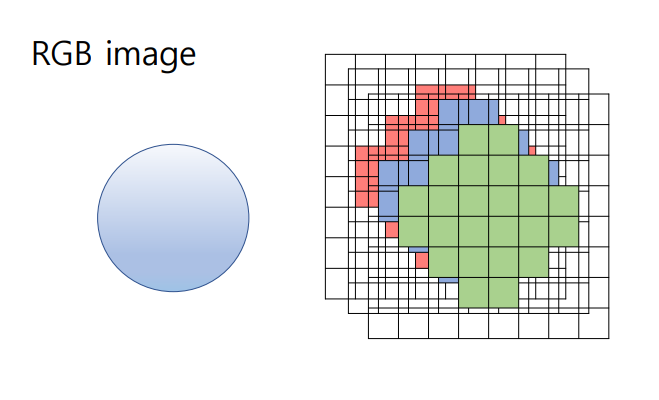
- Python Imaging Library (PIL)(=Pillow) : 이미지 파일을 열고 저장하고 이미지를 조작하는 데 사용되는 파이 라이브러리
- Image.open(경로) : 이미지 파일의 경로를 받아 이미지 파일을 열고 이미지 객체를 생성
- 이미지객체.convert() : 이미지의 형식(JPEG, PNG, GIF 등) 또는 모드(grayscale, rgb)를 변환
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
image_path = './lena.png'
img = Image.open(image_path)
img_bw = img.convert('L') #gray scale이미지
img_rgb = img.convert('RGB') #rgb scale이미지
#이미지를 numpy의 3차원 행렬로 변환하여 plotting 해보기
image_array = np.array(img_rgb)
gray_array = np.array(img_bw)
plt.subplot(121) #1행2열 1번째 서브플롯
plt.imshow(image_array)
plt.axis('off')
plt.subplot(122) #1행2열 1번째 서브플롯
plt.imshow(gray_array, cmap='gray')
plt.axis('off')그레이스케일 이미지는 각 픽셀의 밝기 값만 저장하기에 cmap을 통해 색을 지정해준다.
노이즈(noise)
:: 신호나 데이터에서 발생하는 무작위한 또는 불규칙한 변동 (원래 데이터에 포함되어 있지 않은 잡음정보)
이미지나 비디오의 품질을 저하, 올바른 객체 검출, 분할, 인식 및 추적을 어렵게 만든다.
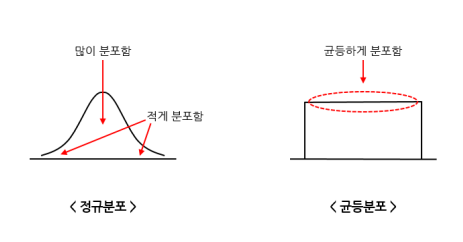
- Gaussian noise : 통계적인 성격을 가지는 노이즈, 노이즈값이 가우스 분포(정규분포)로 구성된다. (평균0, 표준편차1)
- Salt and pepper : 일부 픽셀을 극단적으로 어둡게(검정색, 소금, 0) 또는 밝게(흰색, 후추, 255) 만드는 노이즈
( 이미지 취득 과정, 저장 과정에서 데이터 손실될 경우에 발생 )
- Uniform noise : 노이즈값이 동일한 확률 분포(균일분포)로 구성된다.
cv2란? OpenCV(Open Source Computer Vision Library)
: 컴퓨터 비전 및 이미지 처리 작업을 위한 오픈 소스 라이브러리
- cv2.split: 컬러 이미지에서 B(Blue), G(Green), R(Red) 채널에 속한 픽셀 값을 반환 (BGR (Blue-Green-Red)순서)
- cv2.randn(dst, mean, stddev): 주어진 평균과 표준편차를 가지는 가우시안 분포(정규 분포)에 따라 난수를 생성(채널별 노이즈)
- cv2.add : 두 개의 배열 또는 이미지를 더하여 반환
- cv2.merge: 여러 개의 채널로 분리된 배열을 병합하여 컬러 이미지를 생성하여 반환
- np.random.randint(low, high, size) : 주어진 범위 내에서 무작위 정수를 생성
- np.random.uniform(low, high, size) : 주어진 범위 내에서 모든 값이 동등한 확률로 발생하는(균등분포) 난수를 생성한다.
image_size = (256, 256, 3) #원본이미지
test_image = np.zeros(image_size, dtype=np.uint8) #노이즈이미지 : 0채움(0~255를 채워서 이미지 표현)
#Gaussian noise apply
b, g, r = cv2.split(test_image) #노이즈 이미지의 B, G, R 채널을 분리하여 반환
mean = 0
stddev = 150
#gaussian값을 담을 각 채널배열 생성
gaussian_noise_b = np.zeros_like(b)
gaussian_noise_g = np.zeros_like(g)
gaussian_noise_r = np.zeros_like(r)
cv2.randn(gaussian_noise_b, mean, stddev) #B 채널의 노이즈 값들(평균0, 분산150의 정규분포)을 생성하고 할당
cv2.randn(gaussian_noise_g, mean, stddev) #G 채널의 노이즈 값들(평균0, 분산150의 정규분포)을 생성하고 할당
cv2.randn(gaussian_noise_r, mean, stddev) #R 채널의 노이즈 값들(평균0, 분산150의 정규분포)을 생성하고 할당
noise_b = cv2.add(b, gaussian_noise_b) #기존 B채널에 생성한 노이즈를 입힘
noise_g = cv2.add(g, gaussian_noise_g) #기존 G채널에 생성한 노이즈를 입힘
noise_r = cv2.add(r, gaussian_noise_r) #기존 R채널에 생성한 노이즈를 입힘
image_noise = cv2.merge([noise_b, noise_g, noise_r])
#salt and pepper apply
noise_probability = 0.02 #노이즈를 추가할 픽셀의 비율(전체 픽셀의 2%)
num_noisy_pixels = int(noise_probability * test_image.size) #노이즈를 추가할 픽셀 수
salt_and_pepper_noise = test_image.copy() #노이즈 적용 이미지생성(원본복사)
salt_coords = [np.random.randint(0,i-1,num_noisy_pixels) for i in test_image.shape[:-1]] # Salt 노이즈가 발생할 픽셀좌표 랜덤생성
pepper_coords = [np.random.randint(0,i-1,num_noisy_pixels) for i in test_image.shape[:-1]] # pepper 노이즈가 발생할 픽셀좌표 랜덤생성
salt_and_pepper_noise[salt_coords[0], salt_coords[1],:] = 255 #salt_coords 픽셀의 모든 채널 값을 255로 설정하여 흰색 노이즈 발생
salt_and_pepper_noise[pepper_coords[0], pepper_coords[1],:] = 0 #pepper_coords 픽셀의 모든 채널 값을 0으로 설정하여 검은색 노이즈 발생
#uniform noise apply
min_noise_value = -50
max_noise_value = 50
#-50~50사이의 정규분포를 따르는 난수들을 생성-> 8비트 정수로 표현한 이미지 행렬
uniform_noise = np.random.uniform(min_noise_value, max_noise_value, test_image.shape).astype(np.uint8)
image_with_uniform_noise = cv2.add(test_image, uniform_noise)
출력시 OpenCV에서 이용하는 BGR 색상 순서를 RGB로 변환해야함
(Matplotlib과 같은 다른 라이브러리에서 이미지를 정확하게 표시하기 위함)
plt.figure(figsize=(12,4))
#original image plot
plt.subplot(1,4,1)
plt.imshow(cv2.cvtColor(test_image, cv2.COLOR_BGR2RGB))
plt.title('original')
plt.axis('off')
#gaussian noise image plot
plt.subplot(1,4,2)
plt.imshow(cv2.cvtColor(image_noise, cv2.COLOR_BGR2RGB))
plt.title('Gaussian noise')
plt.axis('off')
#salt-and-pepper noise image plot
plt.subplot(1,4,3)
plt.imshow(cv2.cvtColor(salt_and_pepper_noise, cv2.COLOR_BGR2RGB))
plt.title('salt-and-pepper')
plt.axis('off')
#uniform noise image plot
plt.subplot(1,4,4)
plt.imshow(cv2.cvtColor(image_with_uniform_noise, cv2.COLOR_BGR2RGB))
plt.title('uniform noise')
plt.axis('off')
plt.tight_layout()
plt.show()
각 노이즈 출력결과 + lena이미지에 입혀본 결과
가우스노이즈는 노이즈 값이 평균적이라서 시각적으로 부드럽게 변동하는 경향이 있고
유니폼노이즈는 노이즈 값이 이산적이라서 시각적으로 불규칙한 효과를 준다.
극단적인 0과 255값만 가지는 소금과 후추 노이즈는 유니폼노이즈의 한 종류라고 볼 수 있다.
엣지 검출(Edge detection)
:: 컴퓨터 비전 및 이미지 처리 작업에서 중요한 전처리 단계 => 윤곽 추적, 객체 검출, 객체 인식, 세분화, 특징 추출 등 고급작업의 기반
HOW? Texture Change (질감 변화), Shape Change (형태 변화), Depth Discontinuity (깊이의 불연속성) 등..
그 중 intensity change(채널값의 강도 변화)를 탐지하여 edge를 찾는 법이란?
밝기 에지 (Brightness Edges) : 그레이스케일 이미지에서 밝기(또는 명도) 차이에 따른 에지
색상 에지 (Color Edges) : 컬러 이미지(RGB 이미지)에서 색상 변화에 따른 에지
강도변화는 도함수(gradient) 정보를 활용하여 알아볼 수 있다.
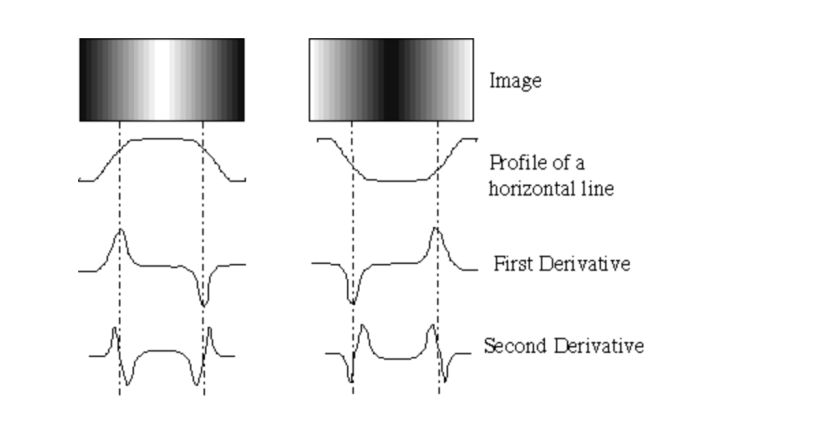
- Derivatives(도함수) : 하나의 픽셀, 작은 지역에서 이미지의 밝기 값 또는 픽셀 값의 변화율
- Gradient(그래디언트) : 이미지의 모든 픽셀에서 밝기 값의 변화율을 나타내는 벡터
주로 라플라시안(Laplacian)(= second derivative, 함수의 두 번째 도함수, △ , ∇²) 값으로 edge detection을 수행한다.
cv2.Sobel( 대상이미지, 데이터타입, x방향미분차수, y방향미분차수, 소벨커널 ) : X와 Y 방향에 대한 미분을 계산하고 결합하여 엣지를 파악하는 소벨필터를 사용하여 엣지검출을 수행하는 함수
cv2.Laplacian( 대상이미지, 데이터타입, 소벨커널 ) : 이미지에서 라플라시안(Laplacian) 미분을 수행
=> 이때 각 커널사이즈를 3x3으로 통일하여 성능을 동일하게 해서 수행해본다.
#x방향 미분 두번
dx2 = cv2.Sobel(image, cv2.CV_64F, 1, 0, ksize=3 )
dx2 = cv2.Sobel(dx2, cv2.CV_64F, 1, 0, ksize=3)
#y방향 미분 두번
dy2 = cv2.Sobel(image, cv2.CV_64F, 0, 1, ksize=3 )
dy2 = cv2.Sobel(dy2, cv2.CV_64F, 0, 1, ksize=3)
#laplacian method
laplacian = cv2.Laplacian(image, cv2.CV_64F, ksize=3 )
이러한 중요정보인 Derivative에 noise가 영향을 미치게 된다. ( 미분은 노이즈에 굉장히 취약함 )

* 노이즈 스무딩(Noise smoothing) : 노이즈로 인한 데이터의 변동성을 줄이기 위해 데이터를 처리하는 과정
=> 시각적 품질을 개선하거나 후속 분석 및 처리 작업을 용이 but 이미지의 세부 정보를 일부 손실 가능성이 존재한다.
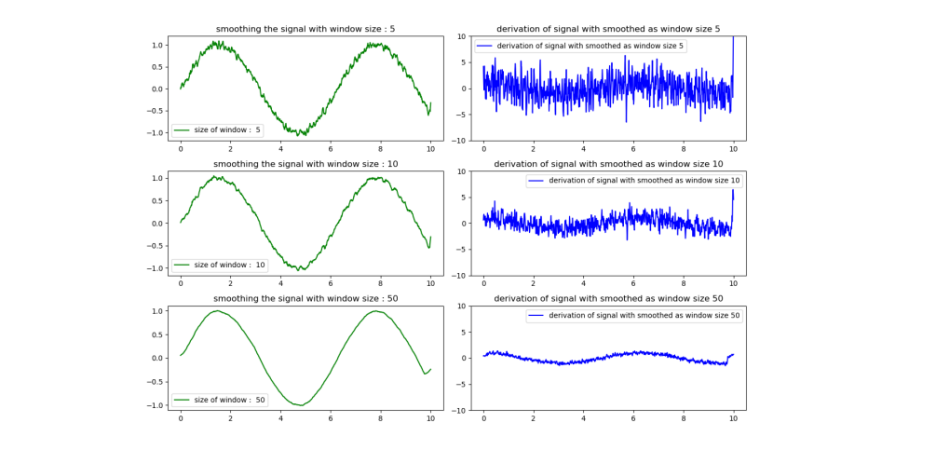
Window size (스무딩 필터의 크기) : 주변 픽셀의 값을 조작하여 이미지에서 노이즈를 감소하는 크기
윈도우 사이즈 증가에 대한 Trade off -> 노이즈 감소효과가 크고 edge가 부드러워진다 but 작은 세부 사항이 제거(Information loss)되어 Edge가 흐릿해지는 부작용이 발생한다.(부정확한 edge)
Intensity change를 Derivatives(도함수)를 사용하여 에지(edge)를 감지하는 방식
• LoG : Laplacian of Gaussian - 가우시안 스무딩을 적용한 이미지에서 라플라시안 연산을 수행하여 에지를 감지
• DoG : Difference of Gaussians - 가우시안 필터 간의 차이를 계산하여 에지를 검출하는 방법
• Sobel edge detection - 이미지의 각 픽셀에서 밝기의 변화율을 수평 및 수직 방향으로 계산하고 조합
• Canny Edge detector - 여러 단계의 처리를 통해 에지를 감지하며 그 중 하나는 그래디언트를 계산하여 에지를 찾는다.
Morphology for binary image(모폴로지 연산)
:: 이진 이미지의 모양, 구조 및 특징을 분석하고 조작하는 것
이는 이미지 내 특정한 패턴이나 객체를 추출, 이미지 내 잡음 제거, 이미지에 연결된 구성 요소를 분리하는 목적의 연산이다.
이진 이미지(binary image) : 0과 1의 픽셀값만 가지는 이미지 = 흑백 이미지(흰색과 검은색 픽셀로 구성)
- Erosion(침식) : 구성 요소 크기축소, 객체분리(간격확보), 작은 잡음을 제거, 이미지 축소 ==> ( 간단한 구조 ) / 커널(Structuring Element Kernel)을 이미지 위로 이동시키면서 이미지와 겹치는 부분을 최소값 픽셀로 대체
- Dilation(팽창) : 구성 요소 크기확장, 객체연결(간격축소), 잡음제거후 매움, 이미지확대 ==> ( 특정구조의 강조) / 커널(Structuring Element Kernel)을 이미지 위로 이동시키면서 이미지와 겹치는 부분을 최댓값 픽셀로 대체
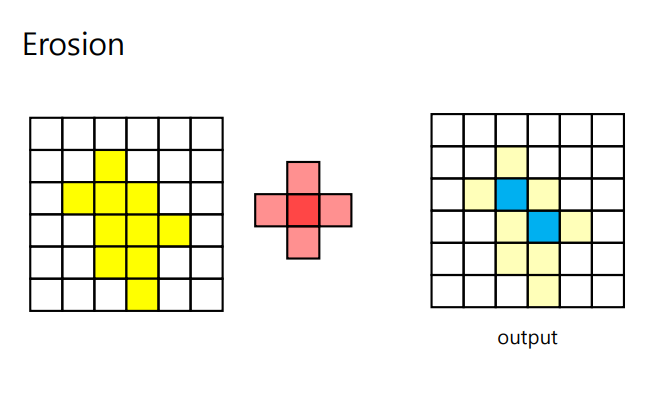
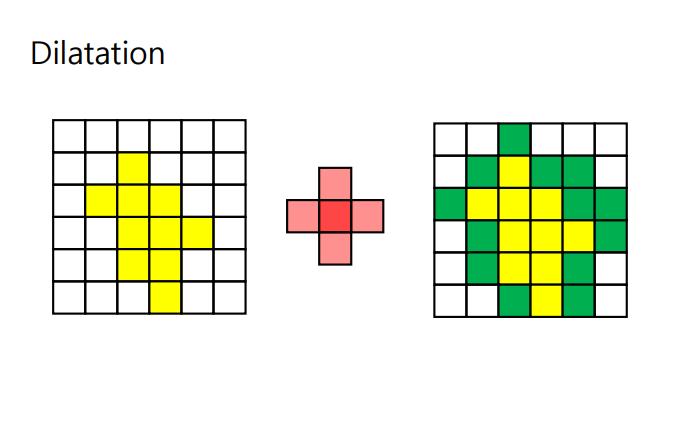

- Opening 작업 : 이미지에서 작은 노이즈나 작은 세부 정보를 제거하고 이미지의 주요 특징을 강조하는 필터링 기술 ( erosion -> dilatation)
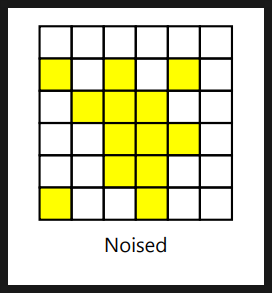
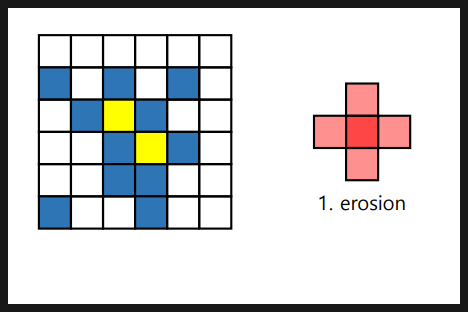
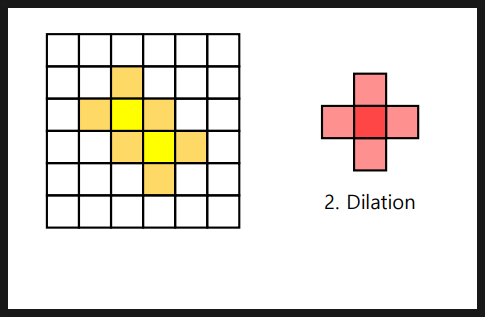
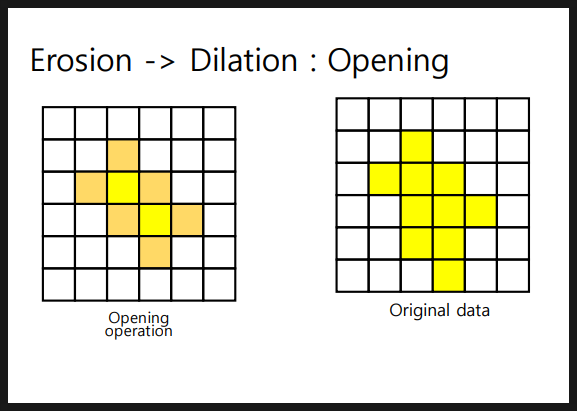
주요한 특징은 보존하면서 작은 구멍을 메우고 작은 객체를 제거한다.
결과적으로 객체의 경계가 부드러워지고, 작은 객체나 세부 정보가 사라진다. => 노이즈 제거에 적합
- Closing 작업 : 작은 구멍을 메우거나 작은 분리된 객체를 결합하여 주요 객체를 더 명확하게 만드는 필터링 기술( dilatation -> erosion )
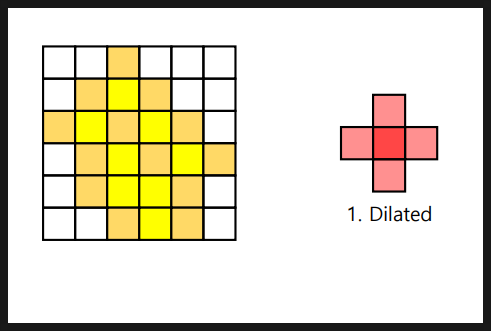
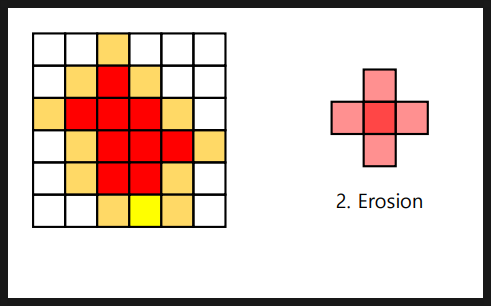
작은 구멍이 메워지고 작은 객체가 결합되어 주요 객체가 뚜렷하게 나타난다.
결과적으로 객체의 경계가 뚜렷해지고 작은 구멍이 메워진다. => 작은 틈을 메우고 객체강조에 적합
검은노이즈, 흰 노이즈를 가지는 이미지를 가지고 모폴로지를 실습해본다.
- cv2.circle(img, center(중심좌표), radius, color, thickness, lineType, shift) : 원그리기
import cv2
import numpy as np
import matplotlib.pyplot as plt
#image 크기와 배경색상 정의
image_size = (256, 256)
background_color = (0,0,0) #RGB값이 모두 0 : 검은색배경
image = np.zeros((image_size[0], image_size[1], 3), dtype=np.uint8)
#image_size와 같은 이미지, 3채널의 컬러이미지로 생성
image[:] = background_color #모든 픽셀
#원 그리기
center_coordinates = (128, 128)
R = 100 #반지름
yellow_color = (0, 255, 255) #G,R의 값이 최대로 채워진 노란색
contour_color = (255, 0, 0) #B의 값을 가지는 원의 경계선
cv2.circle(image, center_coordinates, R, yellow_color, thickness=cv2.FILLED )
cv2.circle(image, center_coordinates, R, contour_color, thickness=2) #테두리처리
noise_prob = 0.02
#이미지에 흰색 노이즈 추가
num_noise_pixels = int(noise_prob*(image_size[0]*image_size[1]))
noise_coordinates = np.random.randint(0, image_size[0], size = (num_noise_pixels, 2)) #노이즈의 좌표
for coord in noise_coordinates :
image[coord[1], coord[0]] = (255, 255, 255) #노이즈 좌표에 흰색을 넣어준다.
#이미지에 검은색 노이즈 추가
black_noise_pixels = int(noise_prob*(image_size[0]*image_size[1]))
noise_coordinates = np.random.randint(0, image_size[0], size = (num_noise_pixels, 2)) #노이즈의 좌표
for coord in noise_coordinates :
image[coord[1], coord[0]] = (0, 0, 0) #노이즈 좌표에 검은색을 넣어준다.
cv2.imwrite('yellow_circle_with_noise.png', image)
plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)) #cv2의 BGR형식 -> plt의 RGB형식으로 변환
plt.title('yellow circle with noise')
plt.axis('off')
plt.show()
cv2.morphologyEx( image대상, cv2.MORPH_OPEN, kernel지정 ) : opening 작업 함수
import cv2
import numpy as np
import matplotlib.pyplot as plt
image = cv2.imread('./yellow_circle_with_noise.png')
#kernel : 5 X 5의 사각형 커널 이용
kernel = np.ones((5,5), np.uint8)
#opening 연산
opening_result = cv2.morphologyEx( image, cv2.MORPH_OPEN, kernel=kernel)
#결과 시각화 생략

cv2.morphologyEx( image대상, cv2.MORPH_CLOSE, kernel지정 ) : closing 작업 함수
import cv2
import numpy as np
import matplotlib.pyplot as plt
image = cv2.imread('./yellow_circle_with_noise.png')
#kernel : 5 X 5의 사각형 커널 이용
kernel = np.ones((5,5), np.uint8)
#opening 연산
closing_result = cv2.morphologyEx( image, cv2.MORPH_CLOSE, kernel=kernel)
#결과 시각화 생략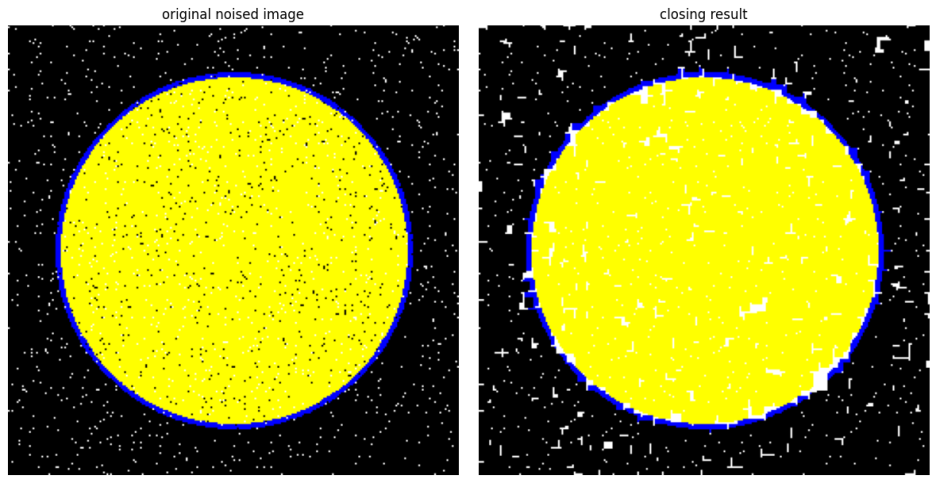

cv2.absdiff(image1, image2 ) : 두개의 이지간 픽셀의 절대차이를 계산한다. erosion_result와의 절대차이를 계산하면 erode한 영역을 구해볼 수 있을 것이다.
import cv2
import numpy as np
import matplotlib.pyplot as plt
image = cv2.imread('./yellow_circle_with_noise.png')
#erosion을 위한 커널
kernel = np.ones((3,3), np.uint8)
erosion_result = cv2.erode(image, kernel, iterations =1)
plt.figure(figsize=(12,6))
difference_result = cv2.absdiff(image, erosion_result)
#결과 시각화 생략 ( 각각 subplot(1,3,1) (1,3,2) (1,3,3)에 출력해서 비교해본다.
이때 테두리선도 difference(erode 대상)으로 도출된 것을 볼 수 있다. => 이는 엣지검출을 수행함을 말한다.
• Top hat :
( Opening 연산 수행 -> Closing 연산 수행 -> 차분(Difference) 계산 ) :: 작은 세부 정보나 객체가 강조된 이미지
의료 영상에서 작은 결절 또는 혈관을 감지하거나 텍스트 이미지에서 작은 문자 또는 노이즈를 감지
• Black hat
( Closing 연산 수행-> 원본 이미지와 Closing 결과의 차이 계산 ) :: 어두운 객체나 패턴이 강조된 이미지
밝은 배경에서 어두운 객체를 찾거나 어두운 세부 정보를 분석하는 데 유용
cv2.morphologyEx( image대상, cv2.MORPH_TOPHAT, kernel지정 ) : tophat 작업 함수
import cv2
import numpy as np
import matplotlib.pyplot as plt
image = cv2.imread('./yellow_circle_with_noise.png')
kernel = np.ones((3,3), np.uint8)
tophat_result = cv2.morphologyEx( image, cv2.MORPH_TOPHAT, kernel)
#결과 시각화 생략
cv2.morphologyEx( image대상, cv2.MORPH_BLACKHAT, kernel지정 ) : blackhat 작업 함수
import cv2
import numpy as np
import matplotlib.pyplot as plt
image = cv2.imread('./yellow_circle_with_noise.png')
kernel = np.ones((3,3), np.uint8)
blackhat_result = cv2.morphologyEx( image, cv2.MORPH_BLACKHAT, kernel)
#결과 시각화 생략
어두운 노이즈가 강조된다 (밝은 영역을 지우는 효과)
3major CV tasks로 object recognition, object detection, object segmentation이 있다.
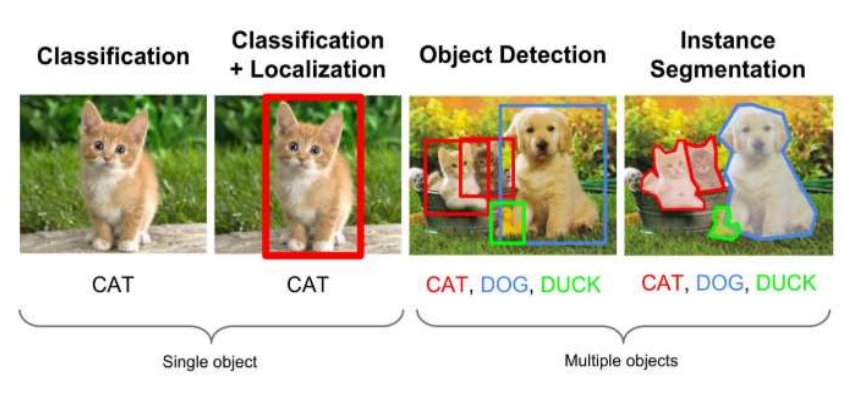
- object recognition : 이미지의 종류를 파악(classification)
- object detection : 객체의 위치파악하여 bounding box 형성(localization) + 이미지의 종류 파악(classification)
- object segmentation : 객체의 정확한 픽셀위치 파악하여 경계선 형성 + 이미지의 종류 파악(classification)
Object recognition(객체인식)
:: 이미지에서 객체 또는 물체를 식별하고 인식하는 프로세스
ImageNet Large Scale Visual Recognition Challenge에서 우수한 성능을 보인 딥러닝 기반 모델 Alexnet, VGGnet, ResNet, DenseNet, Transformer 등이 있다.
Object recognition는 이미지를 분류를 위한 특징추출(feature extraction) 기능이 매우 탁월 -> 다른 task에서 backbone으로 많이 활용된다.
* 다양한 성능지표(matrix)
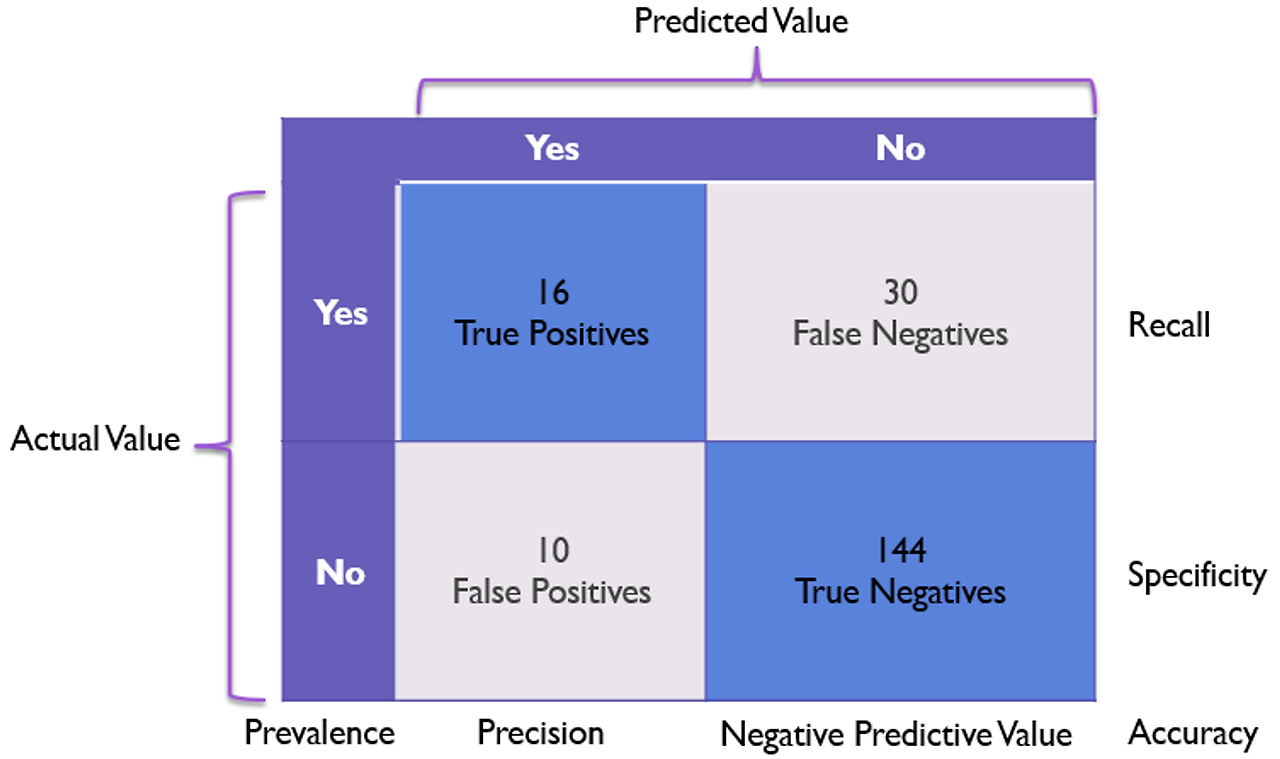
Precision(정밀도) = TP/(TP+FP) : 모델이 positive로 예측한 경우 중 실제로 positive일 확률
Recall(재현율) = TP/(TP+FN) : 실제로 positive인 경우 중 모델이 positive로 제대로 예측한 확률
=> 두 지표는 tradeoff의 관계를 가진다.
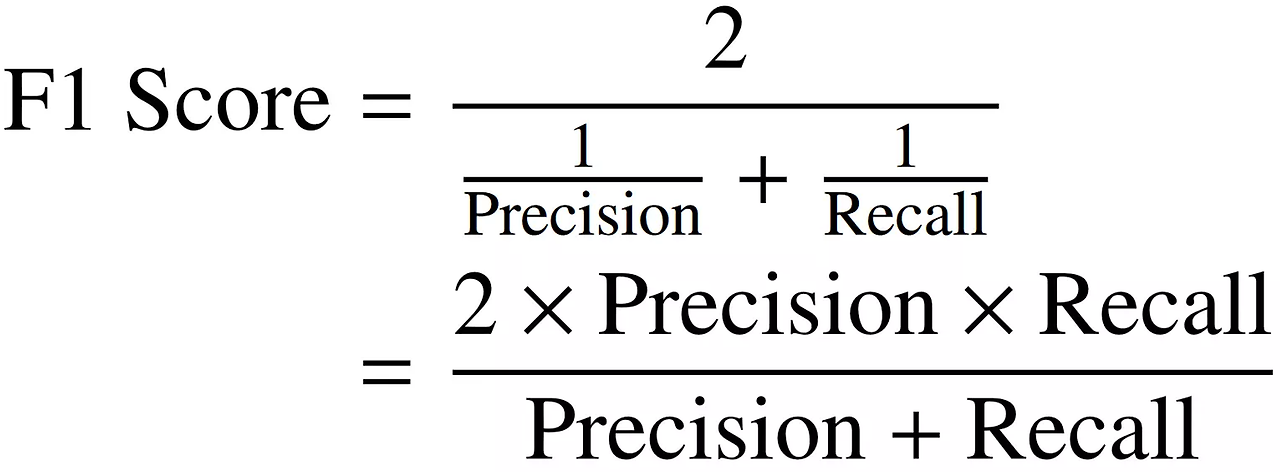
F1 score : precision과 recall을 모두 고려한 성능평가지
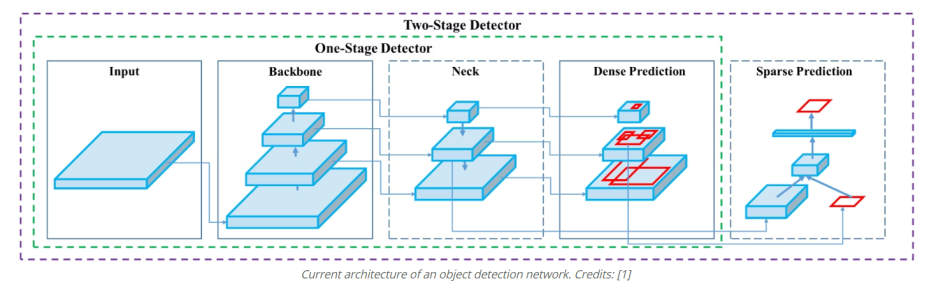
object detection(객체감지)
:: 이미지에서 객체의 위치와 클래스(물체의 종류)를 식별하는 과정
- 작업내용
- localization(region proposal) : 객체의 위치파악하여 bounding box 형성 = 위치탐색작업
- classification : 이미지의 종류 파악 = 분류작업
- 종류
- two-stage detector : 위치탐색(region proposal)(RPN방식)과 분류(classification) 순차수행 (정확도 높음) ex. RCNN(AlexNet백본), FastRNN(VGGNet 백본), FasterRNN(여러개 백본)
- one-stage detector : 위치탐색(region proposal)(grid cell방식)과 분류(classification) 동시수행 (연산속도 빠름-> 실시간 이용) ex. YOLO(darknet 백본), SSD(VGGNet 백본)
- region proposal method(위치탐색 방식)
- grid-cell : 전체이미지를 n*n의 셀로 나누고 해당 객체가 어느 셀에 위치했는지 유추(one-stage detector)
- RPN(Region Proposal Network) : 다양한 비율, 크기를 가지 anchor boxes(bounding box 후보군)를 두고 각 경계 상자에 대한 객체의 존재 여부와 위치를 예측한다. (two-stage detector)
- sliding window : 이미지를 격자로 나누고 각 격자 영역에서 객체를 검출하기 위해 작은 윈도우(영역)를 이동한다. anchor box의 중심이 어디에 위치하는지 찾아내는 작업에 활용된다.
- NMS(Non-maximum suppression) : 가장 높은 IoU임계값 가진 경계 상자를 선택하고, 그와 중첩된 다른 경계 상자를 제거하여 최종 검출 결과를 생성한다.

- object detection model architecture
- Backbone : 입력이미지를 feature map으로 변형 ( 이미지넷으로 훈련시킨 VGG, ResNet 등을 주로 이용 )
- Head : 클래스를 분류하고 bounding box를 형성 -> Dense prediction : one-stage detector , sparse prediction : two-stage detector
- Neck : backbone과 head를 연결 ( FPN, PAN 등 ) -> feature map을 정제(refinement) 하고 재구성(reconfiguration)하는 작업
- 성능지표( classification & localization 작업을 모두 평가 )
- accuracy(정확도): 모델이 정확하게 분류한 객체의 비율
- Precision(정밀도) = TP/(TP+FP) : 모델이 positive로 예측한 경우 중 실제로 positive일 확률
- Recall(재현율) = TP/(TP+FN) : 실제로 positive인 경우 중 모델이 positive로 제대로 예측한 확률
- mAP(mean Average Precision) : precision-recall curve의 아래 면적 -> trade off관계의 정밀도, 재현율의 적절한 조절한 결과평가
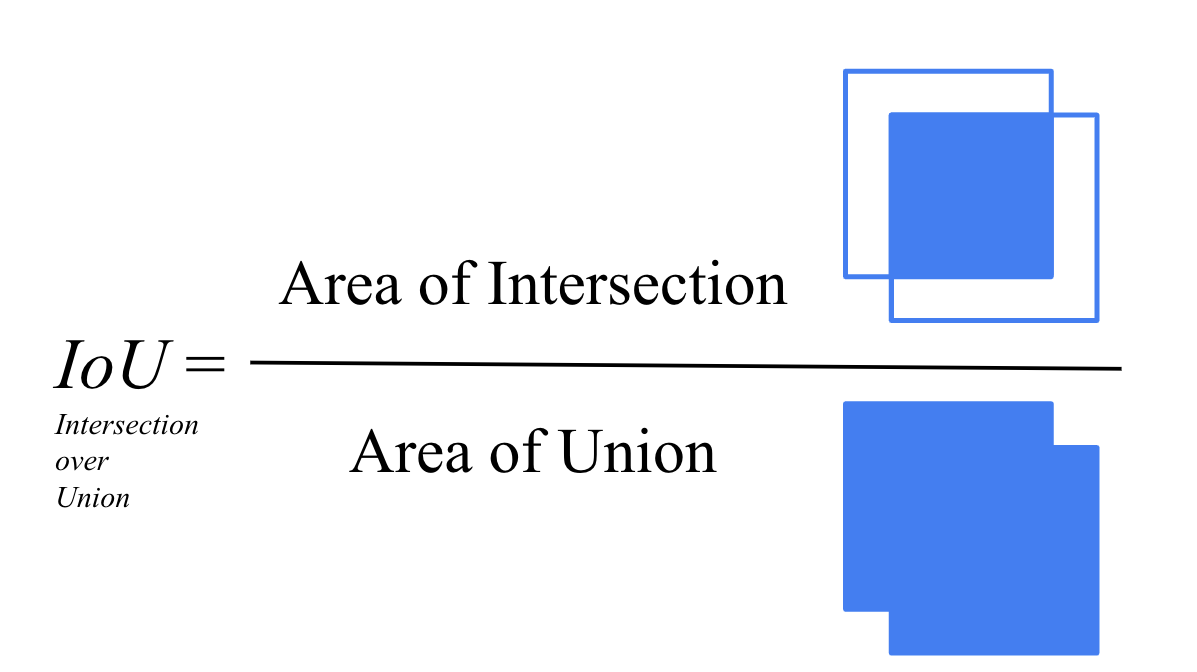
- IoU(Intersecion over Union) : 모델의 bounding box와 실제 bounding box(ground truth) 사이의 겹치는 비율 => 일정기준이상의 IoU를 가지는 bounding box를 TP로 간주하여 평가한다.
Object segmentation(객체분할/세분화)
:: 픽셀 수준에서 이미지 내 객체의 경계를 식별하는 프로세스
- Segmentation의 종류
- Semantic segmentation : 이미지에서 픽셀 수준에서 객체를 식별하고, 각 픽셀에 해당하는 클래스 레이블을 할당( FCN, U-Net, deeplab )
- Instance segmentation : 이미지에서 픽셀 수준에서 객체를 식별하고, 각 객체를 고유한 식별자 또는 인스턴스 ID로 구분( Mask R-CNN = FCN + R-CNN )
- Panoptic segmentation : 시맨틱 세그멘테이션과 인스턴스 세그멘테이션을 결합 ( 객체 클래스로 분류 & 개체의 개별 식별 )

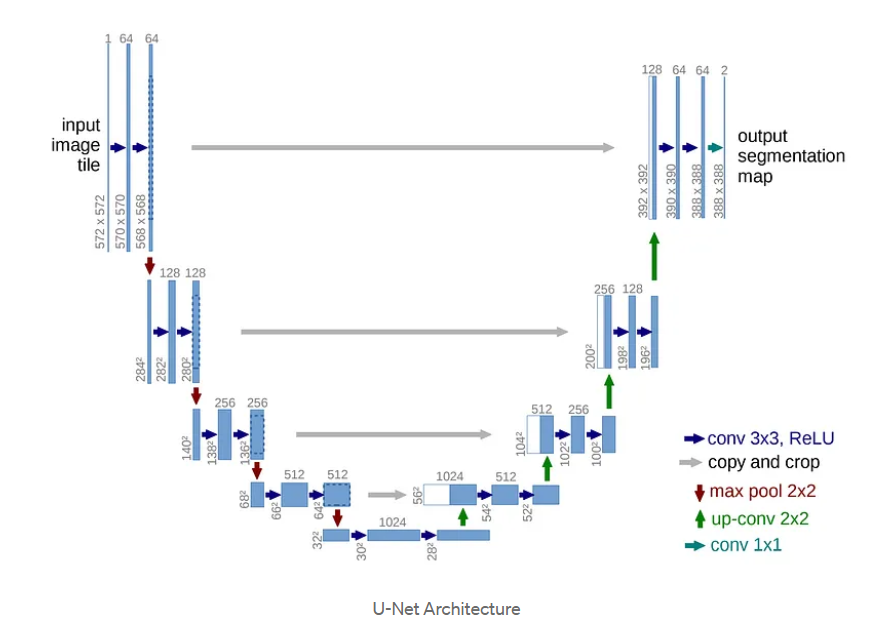
- U-Net
: 이미지의 전반적인 context 정보를 얻기위한 네트워크와 정확한localization를 위한 네트워크가 대칭 형태로 구성된다. 생명의료계열에서 매우 유명한 모델(biomedical image segmentation) (ex. 세포segmentation)
residual connection을 통해 원래의 이미지 정보를 그대로 유지하면서 segmentation을 효과적으로 수행하게 된다.
1) Contracting path(축소 경로) - To contracting context of input image. ( = Down-sampling )
:: 입력 이미지의 Context를 포착하여 특징을 압축시킨다.
- Contracting Step 마다 3x3 convolution을 2회수행 & 활성화 함수 ReLU ( padding 없으므로 줄어듬 )
- Contracting Step 마다 2x2 max-pooling(stride : 2)연산을 수행함 => Feature map의 크기가 절반으로 줄어듬
- 채널수는 2배로 증가한다.
- 단계별 feature들은 residual connection이 이루어져서 concatnate이 된다.
2) Expanding path(확장 경로) - To get fine localization. ( = Up-sampling )
:: 얕은 레이어의 특징맵을 결합하여 높은 차원의 채널(높은 해상도)의 결과를 얻도록 featuremap을 확장시킨다.
- Expanding Step마다 3x3 convolution을 2회수행 & 활성화 함수 ReLU ( padding 없으므로 줄어듬 )
- Expanding Step 마다 2x2 Up-convolution을 수행함 => Feature map의 크기가 2배 증가
- 채널수는 1/2배로 감소한다.
- Up-convolution 된 특징맵을 Contracting path의 테두리가 cropped 된 특징맵과 concatenation함
( * concatnate : residual과 달리 값을 더하지 않고 그대로 붙임. 추출특징을 보존하여 convolution 수행하여 segmentation 성능이 좋아짐 )
( * crop : 업샘플링을 통해 얻은 높은 해상도의 특징 맵을 Contracting path에서 추출된 특징 맵과 동일한 크기로 가장자리를 자르는 작업 => 가운데에 중요한 정보가 많다고 가정한다.. )
최종 출력인 Segmentation map의 크기는 Input Image 크기보다 작다. ( Convolution 연산에서 패딩을 사용하지 않았기 때문 )
'machine learning & deep learning' 카테고리의 다른 글
| [프로젝트 회고] PytorchLightning기반 딥러닝 프로젝트 - 데이터전처리 (0) | 2024.07.19 |
|---|---|
| RNN(순환신경망), LSTM(장단기메모리) 실습 : 주가분석, 영화리뷰분석 (0) | 2024.03.10 |
| 합성곱신경망 : CNN(conventional Neural Network) (0) | 2024.03.10 |
| 머신러닝 기초 & MLP 인공신경망 (0) | 2024.03.10 |